A critical part of museum-digital is the usage of shared controlled vocabularies for actors, places, times, and tags. All museums using museum-digital use these same vocabularies for recording the creation of objects, their use, destruction, etc. Similarly, they are used for a rougher tagging of the objects. Only contacts who are recorded purely for internal purposes – like the current owners of objects – are kept in a separate, museum-specific address book.
On the one hand, using shared controlled vocabularies allows for a centralized editing team. Work that’s been done for one museum is available for all. This allows for a generally higher data quality, improved search options, etc. The only downside to centralized vocabularies is rules: Without everybody following a basic set of rules for the different vocabularies the vocabularies would surely be overcome by chaos quickly.
The two most basic rules are that 1) all entries need to be clearly identifiable and 2) actor names – from actual people to companies and governments to peoples – belong to the controlled vocabularies for actors; place names – cities, countries, streets – belong to the vocabulary for places, and so on. In effect, this means that an actor entry “Gaius Iulius Caesar” (better yet, “Gaius Iulius Caesar (-100–44)”) is a good one. It is clearly identifiable. An actor name “Bosch” should not end up in the controlled vocabularies – there are many people and companies sharing that name. If one means to actually record the German tool maker, one can specify as much using brackets and / or using the full name, e.g. “Robert Bosch GmbH” or “Bosch (tool making company)”.
musdb comes with selection lists enabling a simple reuse of existing vocabulary entries. Where a term or a name has not yet been recorded in museum-digital’s controlled vocabularies, the option to import vocabulary data from Wikipedia / Wikidata and the Gemeinsame Normdatei, and alternatively the need to add a description of at least ten characters enforce some level of identifiable and minimally researched entries.
And then there are imports. During imports, there is no way to force importing users to add additional data. To the contrary, especially during data migrations museums import data from different departments and different decades, leaving one with different spellings for the same person and a very varied quality of the recording overall. Importing thus often means bringing unclean, non-uniform data into the vocabularies. Often enough manual cleanup and enrichment are required to make the data usable – and to stop the “unclean” data from disturbing other users, e.g. by appearing in selection lists and then being falsely linked to another museums entries (a classic example are place entries like “Frankfurt”. Both Frankfurt an der Oder and Frankfurt am Main are significant places – how significant they are depends on where a museum may be located. Leaving the unidentifiable place (name) in the database will easily lead to other museums linking the same entry while actually referring to the other Frankfurt).
Automation can however significantly reduce the work of the colleagues manually editing the vocabularies while also allowing their efforts to have longer-lasting internal benefits to the system. The import tool thus features a number of checks to identify the entries actually referred to. Those checks relevant to the import of references to actors will be introduced over the rest of this blog post.
Rough outline
Actors from (or for) the controlled vocabularies usually enter museum-digital by being linked to objects via events. The same usually happens in the case of imports: The import data states that an object was, e.g., created by a given person. This translates to a new event (what happened to the object? And who did it when and where?) being created. The actor of this event is then set based on the provided name, optionally taking into accounts life dates and links to norm data repositories, in so far as they are made available in the import data.
Preparation
Cleaning the name
To identify the actor name, it is first cleaned and made slightly more uniform on a simple level of spelling.
- Leading and trailing spaces, semi colons, tab stops and newlines are removed
- Duplicate white spaces are removed
- Brackets of the different types (“()”, “{}”, “[]”) are replaced with simple brackets (“()”)
- Unwanted components / specifiers of a name are removed (e.g. “mythological creature” or empty brackets)
- Language-specific name components are replaced with their preferred variants in the vocabularies (German: “d.Ä.” is extended to “(der Ältere)” [the Elder])
- Indicators for uncertainty are stripped from the name, e.g. trailing question marks. They are separately used to identify the certainty of an actor link in a dedicated fields that describes exactly that.
Thus, a name stated in the import data as “; Hans Holbein d.Ä.?” will be imported as “Hans Holbein (der Ältere)”.
Parsing life dates from the input name
If no life dates have been provided explicitly in the import data, they may still be included as part of the actor name. Some museums whose database does not feature dedicated fields for an actor’s date of birth and death will append the years in brackets. Hence, a check is done to see if there are any brackets at the end of the name – and if so, whether the bracket contains a parsable time span. In this case, the time span identified will be used for the actor’s life dates and the brackets’ content will removed from the name (it is not actually a part of the actor’s name after all).
“Hans Holbein (der Ältere) (1465-1524)” with no explicitly provided years of birth and death will thus be transformed to “Hans Holbein (der Ältere)”, born 1465 and dead since 1524.
Identifying the actor
After preparing the inputted actor data, it is checked against the database in various ways. The listed checks below take place in a chronological order. If one returns a positive result and works to identify the actor, no following checks are run.
Checking based on norm data links
If links to external norm data repositories (the Library of Congress authority files, the National Diet Library, the French National Library, etc.) are provided in the import data, the actor vocabulary at museum-digital is checked whether it contains an entry featuring the same external ID. If that is the case, this actor is doubtlessly identified.
Checking global rewrites
For many names, there are different spellings. Similarly, many people use different names over the course of their lives. But the person referred to stays the same.
As not all names are significant enough to be listed as synonyms in their own right, museum-digital features a global (though language-specific) list of “permanent rewrites”. If a museum exported a reference to a “Julius Caesar”, this will be automatically rewritten to “Gaius Iulius Caesar”, thus identifying the person of the same name.
This central list is built and extended as the vocabulary editors do their work. Whenever two actor entries are merged in nodac, editors have the option to mark the name of the actor being merged into the other as to be permanently rewritten.
Checking institution-level rewrites
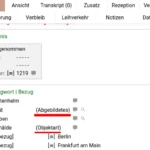
Whenever a new actor entry is added through musdb or by the way of imports, this is marked down in the database. Which museum used what term, resulting in which entry. Which entry may in the future be updated to refer to another. This is most simply explained using an example from the realm of places – the above-used example of “Frankfurt”:
If a museum newly brings “Frankfurt” to the controlled vocabulary for places, an additional entry is made in the database to note that the museum was the first to add an entry named “Frankfurt”, and that that finally resulted in the creation of a new place with the ID #99999. The object data itself makes it clear that the museum actually referred to “Frankfurt am Main” (ID: #217). If the vocabulary editors thus merge “Frankfurt” (#99999) with “Frankfurt am Main” (#217), this obviously cannot be a permanent rewrite. But the museum-specific log can be updated: The museum entered “Frankfurt”, and it referred to the entry #217 (Frankfurt am Main). If the museum thus enters “Frankfurt” without any further specification in the future, the importer and musdb can automatically identify Frankfurt am Main as the place actually referred to. The same logic applies to the import of actor data.
This check is obviously based on the assumption of some level of uniformity between different workers at the same museum. If a museum in Frankfurt an der Oder has almost all of their employees referring to Frankfurt an der Oder as the canonical “Frankfurt”, except for one, this will obviously backfire. But it is to be hoped that this case is rare enough – and that such a very different colleague would recognize their own non-conformity and choose to use the full names for both places to be able to clearly document (and communicate overall) with their colleagues.
Checking by name and life dates
If all the above checks did not work, the actor’s name and life dates are checked against the controlled vocabulary for actors itself. Does anybody with the same name, who was born and died at the provided years, exist in the actor vocabulary (either going by the language-specific translation of the name or by the “base entry” of an any language).
If that is not the case, the actor likely does not exist in the database yet.
Identification failed. Should a new entry be created?
If the actor does not exist in the database yet, they need to be added. Maybe.
Some names are known to be in clear conflict with the rules of the vocabulary for actors.
Checking the blacklist
museum-digital keeps a centralized blacklist for actor names that are known to be in clear conflict to the rules of the actor vocabulary. This list mainly contains either deliberately unspecific actor names (“unknown”; “unidentified”) or very unspecific ones (“John” [a random given name without a family name], “painter” [the name of a profession, not even of the actor themselves]).
If the entered actor name is contained in this blacklist, the attempt to link any actor to the event is aborted. The free-text note about the event is instead extended to mark that an actor of the blacklisted name was noted to be related to the event.
Checking if the actor is actually a place, time, or tag
A classic problem is vocabulary entries being entered in an unsuitable vocabulary – often for simple reasons likely colleagues slipping to a wrong column when working with a table calculation program. And thus one is asked to import an actor “14th century”.
The “14th century” is obviously a time, not an actor. For this, too, there is a centralized list that can be extended using nodac. Whenever the vocabulary editors move an entry from one vocabulary to another, they have the option to mark the entry’s name as always being of the target type.
Say the 14th century was previously entered as a tag. A vocabulary editor moved the entry to the vocabulary for times and marked the string “14th century” as one always referring to a time. If one then attempts to link a new actor “14th century”, the import tool can automatically recognize that this name actually refers to a time and link a time instead of an actor to the event. The attempt to add an actor is thus redirected to a different category.
All else failed: The actor is being added
If all the above checks did neither result in identifying a pre-existing record, nor in identifying the input name as invalid in one way or another, the actor is added to the controlled vocabularies and linked to the event. The entry now needs to be cleaned and enriched manually by the vocabulary editors.