Imagine you have a spreadsheet with potentially unclean data or data that is not confirmed to be interoperable. A museum may want to migrate their data to a different system or share it with an aggregator or a researcher may want to analyze data from different museums where each has their own thesaurus. To make the data legible to an external service or to understand that where one museum says “shoe” and another says “shoes” the exact same thing is meant, it makes sense to check the terms in question against larger (norm data) databases and add their ID for the entity in question. Thus, “shoe” and “shoes” become understandable as the same.
This process is called reconciliation. One of the most used tools to actually connect to external services and reconcile data this way is OpenRefine. But to do so, OpenRefine needs to be able to communicate with such services. The open standard by which they communicate is the Reconciliation API specification. Depending on how completely the API has been implemented, the consuming software may offer additional features such as offering alternatives, suggesting entries or displaying previews of entries made available through the API.
Since this weekend, museum-digital offers such APIs for different types of data.
In md:term, reconciliation APIs were added for each of the available controlled vocabularies. Besides the controlled vocabularies of museum-digital (tags, actors, places, times) this means that users of OpenRefine can now reconcile their data with select other vocabularies such as the Oberbegriffsdatei or the hessische Systematik. Besides implementing exact and partial matching of requested terms, this implementation features previews.
Two additional points are noteworthy in terms of md:term’s implementation of the reconciliation API specification.
1) Similar to museum-digital’s import tool, md:term’s reconciliation service attempts to clean up entered terms before reconciling. As such times are automatically rewritten (“1912 bis 1914” [1912 through 1914] becomes “1912-1914”), question marks and other markers of uncertainty are removed, and – whereever known – autocorrections stored in the city (Frankfurt a.M. > Frankfurt am Main) are applied to the terms.
2) Multilinguality: Whereas the current version of the regular reconciliation API does not consider multilinguality, the above-mentioned auto-corrections and rewriting are language-dependent. And so are previews and names of entities in md:term for museum-digital’s vocabularies. Hence, an additional parameter for the requested language can be supplied.
Reconciliation APIs for md:term may be found on the download page linked in the sidebar. Going this way, the language parameter is automatically set to the user’s current language.
Reconciliation by Inventory Number
To identify objects available published through museum-digital, a reconciliation API now exists in the frontend as well. It can be found at /reconcile/invno/ on each instance of museum-digital (e.g. here for the Hessian instance.
It reconciles entries by their inventory number. An additional number may be added to the URL to search only within a single institution. Where https://hessen.museum-digital.de/reconcile/invno/ allows matching objects by inventory numbers across all institutions publishing their objects on the Hessian instance of museum-digital, the https://hessen.museum-digital.de/reconcile/invno/1 will thus only search within the collections of the Freies Deutsches Hochstift / Frankfurter Goethe-Museum (the institution of the ID 1).
Reconciling GLAM data using the MD:term reconciliation API: an example
As they have much more experience with OpenRefine, I asked the colleagues from digiS whether they could provide a description of how to actually use the reconciliation API from a user perspective. This section is theirs:
Using the reconciliation API in OpenRefine is straightforward (cf. the OpenRefine documentation for a general introduction). Let’s walk through a typical workflow using GLAM data and the MD:term API!
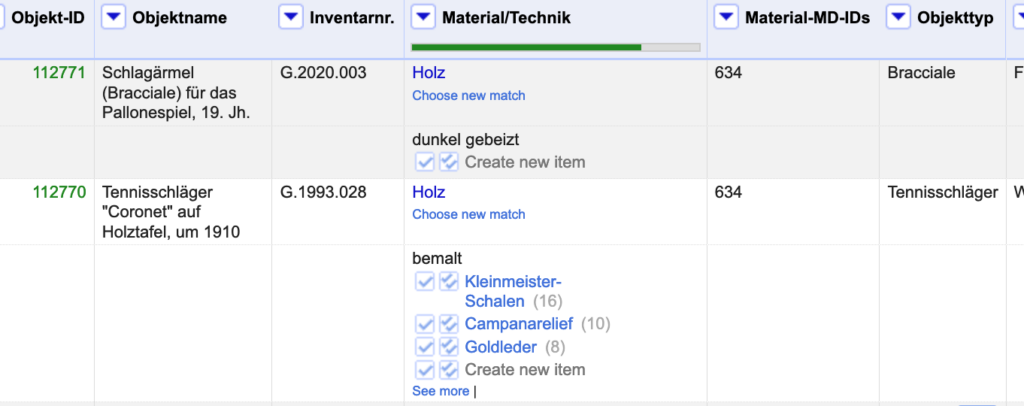
Our sample dataset (adapted from actual data provided by the Sportmuseum Berlin) features, among others, columns on material/technique, object type and places.
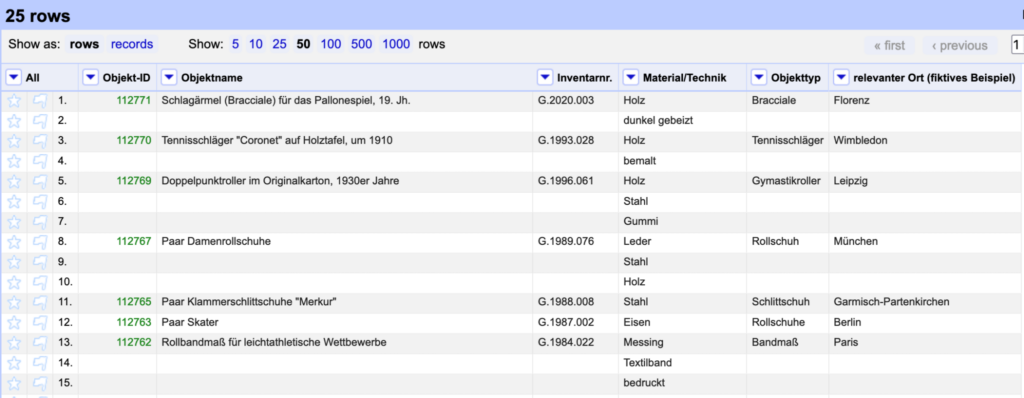
These elements are just strings and consequently not linked to any authority file. Strings are not guaranteed to be unequivocal, nor are they particularly suitable for retrieval, programmatic reuse or multilingual contexts. In order for the data to be as useful as possible, let’s reconcile them with an authority file, in our case the MD:term vocabularies now readily accessible also via a reconciliation API.
If you have never used the MD:term reconciliation service you first have to add it to OpenRefine. Click on the small triangle in the header of the column you want to reconcile. Select Reconcile → Start reconciling.
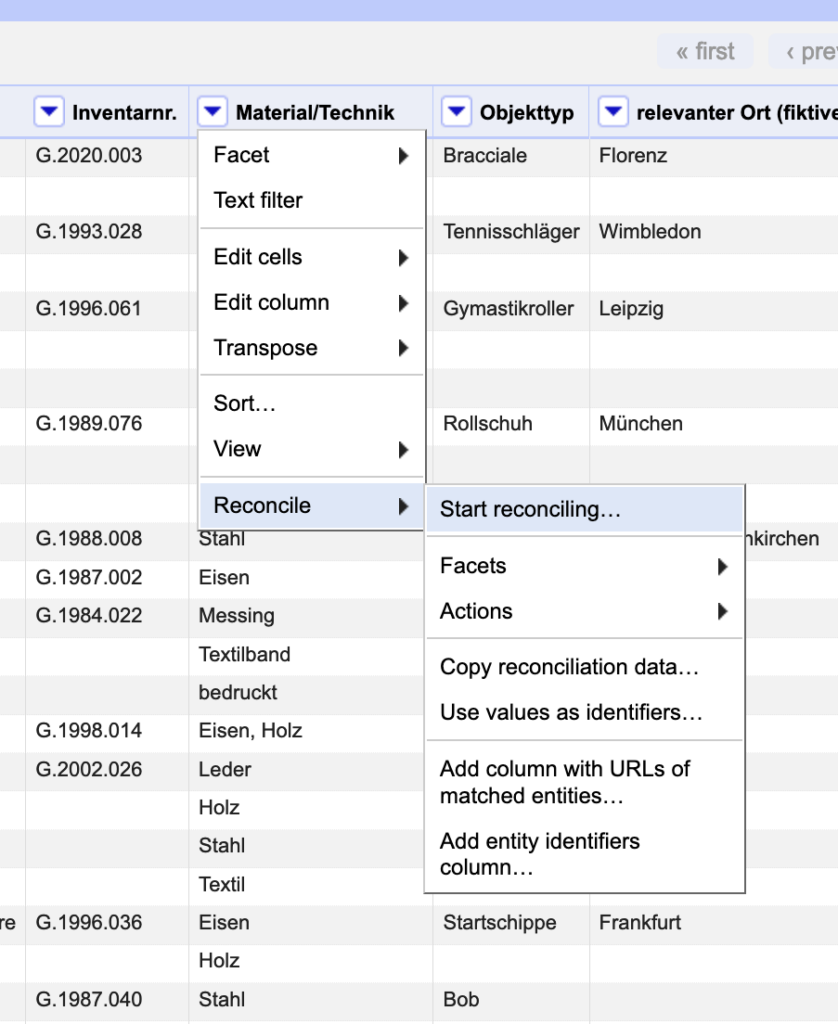
In the following window, add the API endpoint you want to use (cf. https://term.museum-digital.de/downloads for a list of MD:term endpoints).
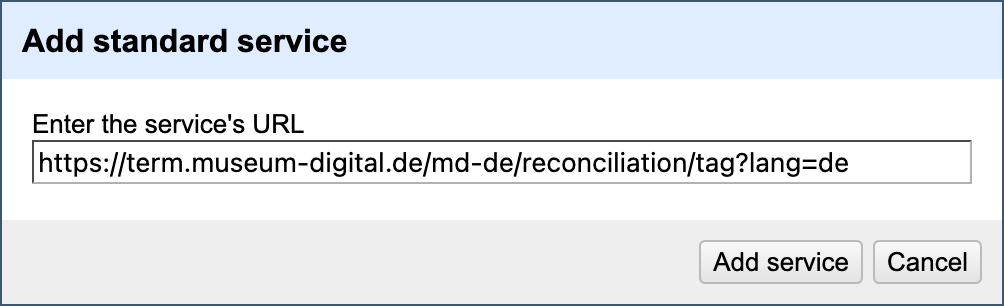
Now you can select the service for reconciliation:

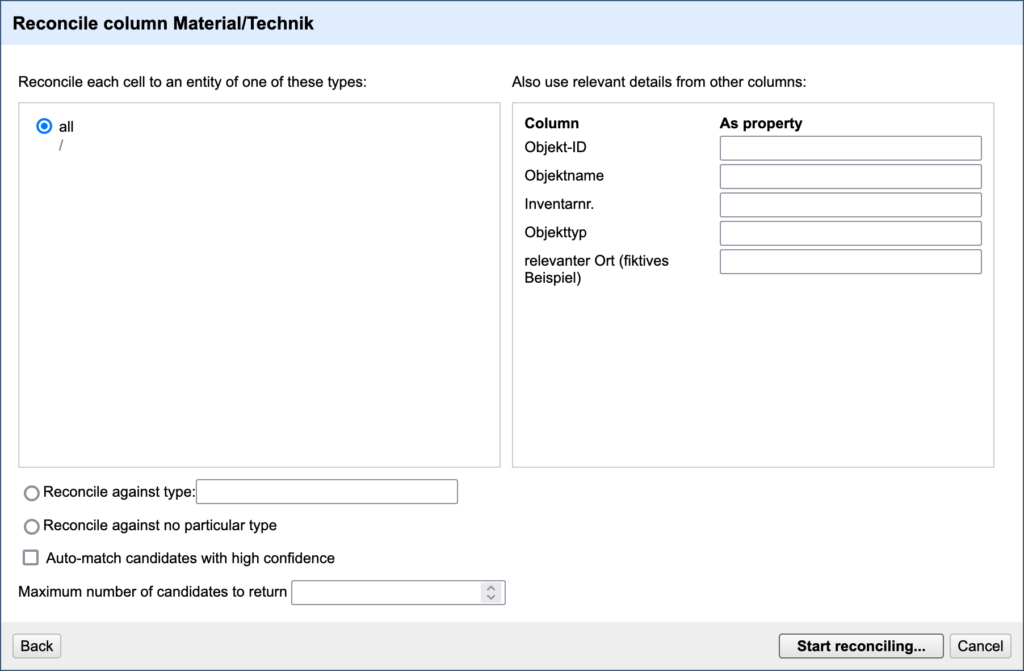
In the following window, the only really important decision you have to take is whether or not to automatically match “candidates with high confidence”. Auto-matching speeds up the whole process, but you have less control over what happens with your data.
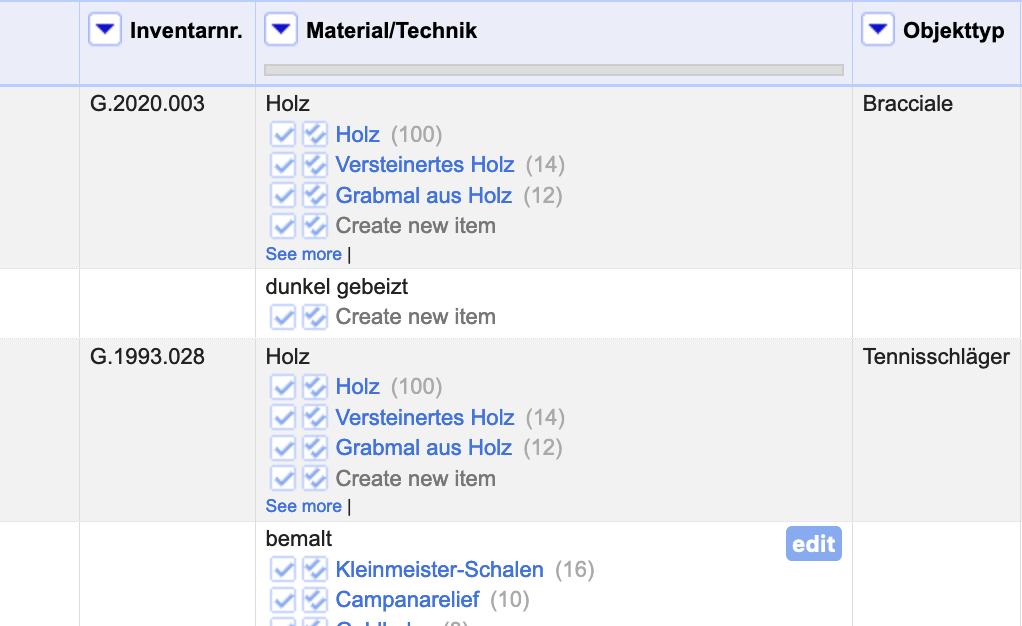
Hit “Start reconciling” to trigger the reconciliation process. You can now see that the strings have become links. In fact, they have been linked to possible entries in MD:term. If you choose the auto-match option, the most probable candidates have been selected automatically. If not, you have to select the candidate you want to match manually by clicking the arrow to the left. One arrow matches the value in the selected row only, two arrow match all identical values in the entire columns automatically.
Once you’re done with the reconciliation you can, for example, write the IDs of the reconciled values into a new column. Click once again on the small triangle on the left side of the top row of the column you’re working on. Go to Reconcile and Add entity identifiers column.
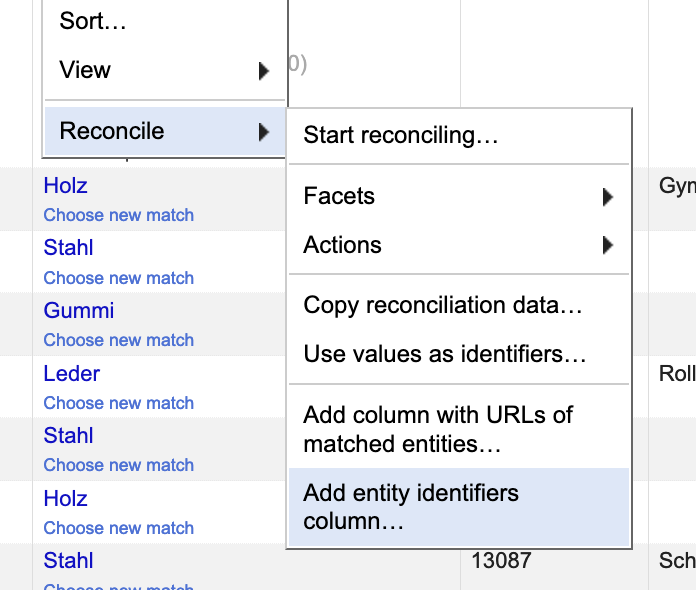
Name the column that is to be added and you will have a new column that contains the MD:term IDs.