

Interoperability has been one of the focal issues around museum-digital practically since its inception. Offering different, simple ways to bring data into the system was a necessary requirement to even think of what we do. And offering simple ways to get the data out of the system again is just good practice – though all too often neglected.
To that end, there have traditionally been two primary ways for data retrieval. In musdb, one could run batch exports and receive a ZIP with some form of XML files. One per object, with the objects matching the results of any given object search.
On the other hand, there is the public API. Using URL manipulation, one can access the (primary) contents of each page in a machine-readable way. To access the JSON representation of an object’s published metadata, where the object’s ID is 7141 in the Hesse instance of museum-digital (URL: https://hessen.museum-digital.de/object/7141), one simply has to insert json to the path: https://hessen.museum-digital.de/json/object/7141.
Next to the default JSON output, additional APIs are offered wherever suitable for a given data type. For objects, the primary additional output method is a LIDO API.
Thus far, the main limitation of the public API was that it only allowed one object (or institution, collection, etc.) to be queried at a time.
Querying Object Metadata in Batches
After a significant refactoring of the code to load object data for object pages – primarily to improve caching and allow for parallelized requests to the database – we are now finally able to offer APIs for querying object metadata in batch. Thanks to grouped database queries, performance and resource usage scale nicely. Taking simply the currently most recent objects in the Germany-wide instance of museum-digital: Loading all object data of one object and presenting it in JSON takes 0.0087 seconds and loading and generating the JSON for the 100 most recent objects takes 0.197 seconds (or 0.00197 per object). Note that not all queries for all aspects of an object’s metadata are grouped yet, performance may thus get even better over time. This does also not yet account for the overhead of the many HTTPs requests one would previously need to execute to get each object’s metadata one by one – real performance improvements are thus even greater.
Now, how to access object metadata in batches?
The batch access is linked with the search API and reuses its main query parameter (“s”). Say, if one is searching for objects related to Berlin (a.k.a. the place of the ID 61), the URL of the respective search page would be https://global.museum-digital.org/objects?s=place%3A61. The corresponding API for retrieving all of the objects’ published metadata would then be https://global.museum-digital.org/export/json/place:61?limit=24&offset=0. Like the search page itself and its primary API (/json/objects), the full batch export API is paginated with a maximum of currently 100 objects per page being returned.
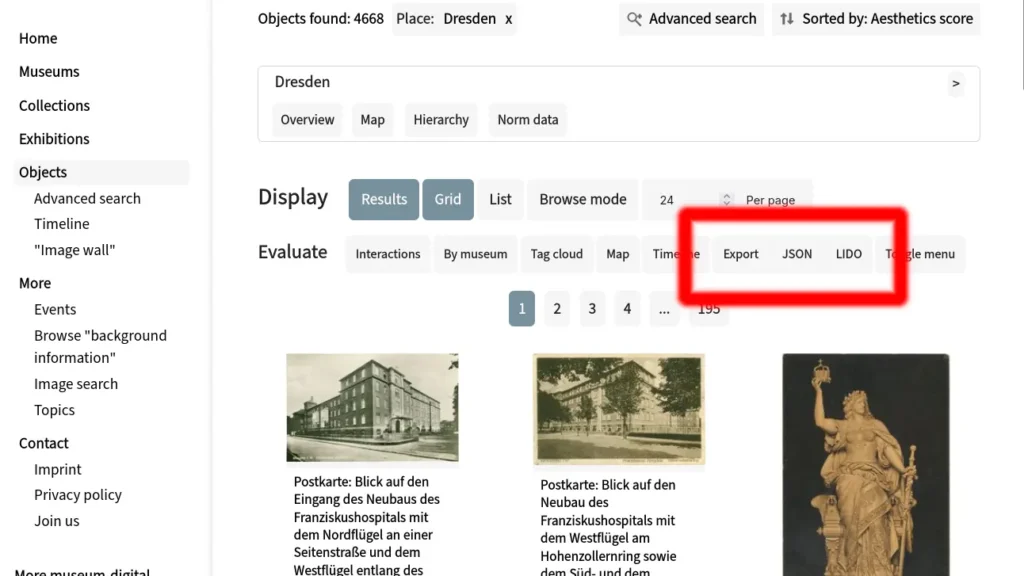
Currently, the batch export of full object metadata is available for JSON and LIDO (XML) representations of the object data. More can rather easily be added later, should a demand arise.
OAI
Implementing a performant way to export full object metadata in bulk was one of the two main missing components for the long-missing implementation of an OAI-PMH API.
OAI is a standard tailored towards data harvesting. Say, an external service like the German Digital Library or Worldcat wants to do something with external data from diverse sources, e.g. to also display objects or implement a search across the different collections / libraries to find which one has which object / book. To be able to do so, they need to be able to access the respective data in some way. Ideally, using a common standard that describes how to query data, helps to identify any data sets that need to be updated or added (or deleted), and finally presents a uniform way to access the data periodically. That, exactly, is OAI-PMH.
In a nutshell: OAI-PMH allows other services to copy all (published) data from another service in a maschine-readable way and can thus significantly improve reuse in aggregation. Of course this only applies to technical questions; legally, potential re-users need to comply with the metadata license applied by the initial data provider regardless of the (technical) means of access.
Since last week, museum-digital now provides a OAI-PMH API at /oai respective to a given subdomain. E.g.: https://hessen.museum-digital.de/oai. As of now, the OAI-PMH API provides access to the objects’ metadata using LIDO (XML) and the mandatory OAI-DC format.
Note that there are some caveats remaining for now: First, the LIDO representation of object metadata is not (and can by definition not be) as complete and fine-grained as the JSON API. It is also not exactly similar to the LIDO as returned by exports from musdb (one is formed natively in PHP, the other using XSLT, leading to divergent development paths). Also, the LIDO output lists different identifiers from the ones used by the OAI-PMH API and the OAI-DC representations otherwise.
Finally, the OAI-PMH API at museum-digital does not implement OAI-PMH data sets to group collections. Instead, it follows the existing search logic (essentially providing a new endpoint per query). Example searches via OAI might thus look as follows:
- All objects from the Agrargeschichte instance of museum-digital, represented in OAI-DC: https://agrargeschichte.museum-digital.de/oai?verb=ListRecords&metadataPrefix=oai_dc
- All objects linked to Berlin (place #61), in the Berlin instance of museum-digital, represented in LIDO: https://berlin.museum-digital.de/oai/place:61?verb=ListRecords&metadataPrefix=lido
- All objects of the Freies Deutsches Hochstift, Frankfurt am Main, represented in LIDO: https://hessen.museum-digital.de/oai/institution:1?verb=ListRecords&metadataPrefix=lido
- All objects from Baranya with only their identifiers: https://ba.hu.museum-digital.org/oai?verb=ListIdentifiers&metadataPrefix=lido
Credits
Credits where credit is due: the Städel Museum deserves praise for their implementation of OAI-PMH. For me personally, seeing the Städel’s API was the first time I saw a visibly stateless OAI-PMH implementation, enabled by the ingenious idea of using machine-readable, JSON-encoded resumption tokens over UIDs that have to be resolved on the server side. I spent weeks (or months?) making museum-digital’s frontend stateless. By following the Städel’s example, it can remain so even while offering an OAI-PMH API.



Mentions
Frontend Verknüpfte Objekte auf Quellen-Seiten sind jetzt sortiert nach Position in Quelle Damit ergibt sich quasi automatisch ein Register für die Quelle Ziel-URL bei Nutzung…
Frontend On source / reference pages, linked objects are now sorted by the position within the source work on which they are referenced or which…
Entwicklung Frontend Anzeige der Transkriptionen auf Objektseite grundsätzlich überarbeitet Titel wird ausgegeben Falls nicht vorhanden werden weiterhin Art (Original vs. Übersetzung) als Ersatz für den…
Development Frontend Significantly reworked the display of transcriptions on object pages Titles of transcriptions are now displayed If none is set, the type of the…