
Im Januar 2021 haben wir im Rahmen von museum-digital unser erstes KI-gestütztes Feature veröffentlicht. Entweder über eine eigene Seite oder eingebettet in den Objekt-Upload-Workflow wurden Bilder klassifiziert und in Tags für Schlagworte umgewandelt. Seit ca. einem Jahr toure ich durch die Lande, und erkläre, warum dieser Anlauf falsch lag.
Mit einem neuen KI-Feature zur Bildklassifikation, das ab Donnerstag Nacht bereit stehen wird, versuchen wir aus unseren Fehlern zu lernen. Bevor dieses vorgestellt wird aber seien die damaligen Fehler besprochen.
Bildklassifikation, Versuch 1
Im ursprünglichen Anlauf zur Bildklassifikation wurden alle Abbildungen zu allen Objekten entweder beim Upload oder über eine gezielt dazu eingerichtete Seite klassifiziert.
Die Abbildungen wurden dabei an ein KI-Modell übergeben, und seine (englischen) Ausgaben mit dem Schlagwort-Katalog von museum-digital abgeglichen. Die gefundenen Schlagworte wurden dann als Schlagwort-Vorschläge angeboten.
KI braucht passende Hardware
KI-Tools arbeiten am besten auf Grafikkarten. Das, was ein herkömmlicher Webserver nicht hat, ist eine Grafikkarte. Also entschieden wir uns für den offensichtlich klugen Weg: Mithilfe von Tensorflow.js wurden die Berechnungen auf die Geräte der gerade eingebenenden User ausgelagert.
Gut: Die Berechnungen liefen nicht mehr auf der ungeeigneten Server-Hardware. Schlecht: Wer einen durchschnittlichen PC in einem kommunalen Museum kennt, sollte wissen, dass er vielleicht eine Grafikkarte haben mag – aber dann höchstwahrscheinlich auch nur eine Office-Grafikkarte aus dem untersten Preissegment. Und vor allem 2021 waren die meisten Laptops nicht besser für KI-Anwendungen geeignet, als die Server-Hardware von museum-digital. Ergo: Die Berechnungen zur Bildklassifikation dauerte lange(!).
Workflows
Schlimmer noch: Die Berechnungen zur Bildklassifikation waren blockierend. D.h., dass man in dem Browserfenster, in dem die Berechnungen ausgeführt wurden, nicht weiter arbeiten konnte. Dadurch, dass die Bildklassifikation in den Objekt-Ersterfassungs-Workflow eingebaut war, verlangsamte sie diesen deutlich.
In der Reflexion lässt sich feststellen, dass, solange keine wirklich gute Hardware zur Verfügung steht, KI-Anwendungen zu Anfang oder zu Ende des Erschließungsprozesses und von diesem getrennt / im Hintergrund eingesetzt werden sollten. Zu Anfang der Erschließung, wenn nur die Inventarnummer und hoffentlich ein Bild vorliegen, kann z.B. Bilderkennung nützlich sein, um Eingabehilfen und Vorschläge zu generieren. Die erratische Natur von KI – meistens richtig, mal falsch, und bei jedem Durchlauf unterschiedlich – spielt somit keine Rolle, weil es sich nur um später von Menschen nachbearbeitete, akzeptierte oder abgelehnte Vorschläge handelt.
Zu Ende des Erschließungsprozesses kann KI sinnvoll eingesetzt werden, um einerseits auf Basis der vorliegenden Daten zusätzliche Datenfelder zu befüllen (KI-generierte Objektbeschreibungen mit Zwischenspeicherung) oder zusätzliche Funktionen, die naturgemäß schwammigen Kategorien folgen anzubieten (Sortierung nach Ästhetik von Thumbnails).
Der Einsatz von KI-Tools in Echtzeit, wie er im ursprünglichen Bildklassifikations-Tool erwartet wurde, kann mit entsprechend guter Hardware sinnvoll sein. Die im Juni vorgestellte, in Zusammenarbeit mit dem Zuse-Institut und digiS testweise bereitgestellte, Erstellung von Objektbeschreibung auf Basis bestehender Metadaten ist ein gutes Beispiel. Im Zuse-Institut kommt hierzu eine Nvidia GH-200 zum Einsatz. Der Preis der Hardware alleine übersteigt das Jahresbudget vieler Museen.
Die Wahl des Modells sei weise getroffen
Weil eben die Hardware unzureichend war und wir eine Bildklassifikation in Echtzeit ermöglichen wollten, waren wir bei der ursprünglichen Bildklassifikation auf kleine, sehr effiziente Modelle angewiesen. Nach einigem Suchen endeten wir bei MobileNet.
MobileNet kommt zwar prinzipiell aus dem richtigen Bereich (Objekterkennung), hat aber offensichtlich sehr anders gelagerte Trainingsdaten. Straßenschilder und Tiere werden auch bei der vorliegenden, mittlerweile veralteren Version recht stabil erkannt. Anderes eher nicht.
Dass ein Modell mit einen der Verschlagwortung im Museumsbereich näheren ursprünglichen Einsatzgebiet bessere Ergebnisse geben sollte, bedarf eigentlich keiner größeren Erläuterung.
Für welche Objekte eignet sich Bildklassifikation?
Die ursprüngliche Bilderkennung hat also technische und organisatorische Probleme. Aber sie hat inhaltliche: Bilderkennung erkennt eben Bilder. Objekte sind Objekte. Eine annähernd deckungsgleiche Übereinstimmung zwischen Bild und Objekt kann vorliegen, muss aber nicht. Meist lässt sich das an Objektarten festmachen: Beschreibt man den Scan einer frühen Fotografie oder eines Ölgemäldes, beschreibt man gleichzeitig das Objekt. Beschreibt man das Foto eines Schranks, hat man wahrscheinlich deutlich weniger über das Objekt selbst und dafür mehr über die Umstände des Fotografierens gesagt.
Auch eine relativ naive, nicht spezifisch auf Objektabbildungen nachtrainierte Bilderkennung kann im Museumsbereich also sinnvoll sein, ihr Nutzen ist aber Kontextabhängig.
Der zweite Anlauf: Bilderkennung für abgebildete Elemente
Ab Donnerstag wird nun eine neue Funktion zur automatisierten Bilderkennung zur Verfügung stehen, die vor dem Hintergrund der Fehler des ersten Anlaufs spezifischer agiert und (hoffentlich) sinnvoller in bestehende Workflows integrierbar ist. Ziel ist die Erkennung von Bildinhalten spezifisch für solche Objekte, bei denen Bild und Objekt annähernd deckungsgleich sind.
Da dies eben nicht alle Objekte sind, muss das Feature spezifisch aktiviert werden. Dies ist über eine neue Einstellung auf Ebene von Sammlungen möglich.
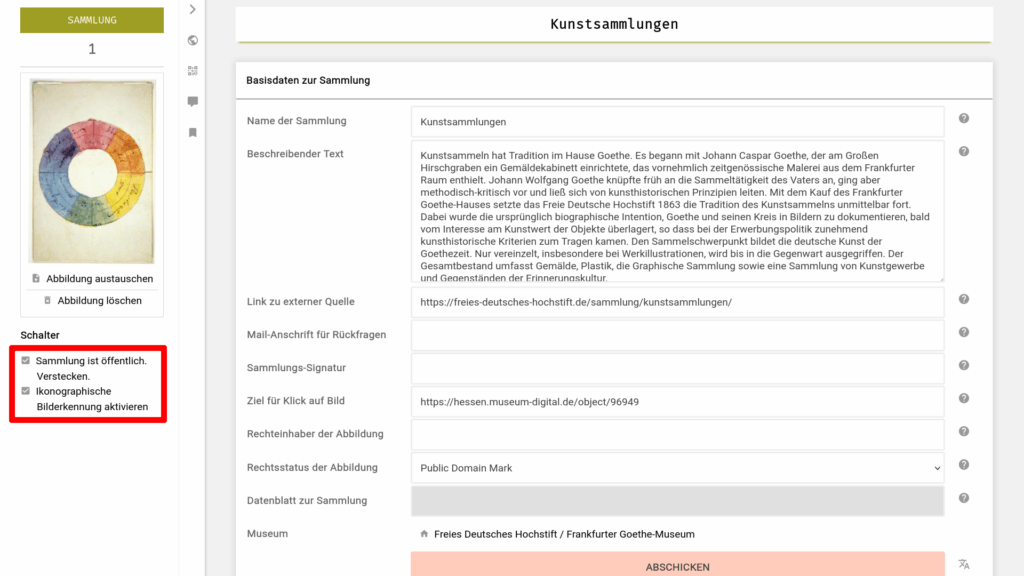
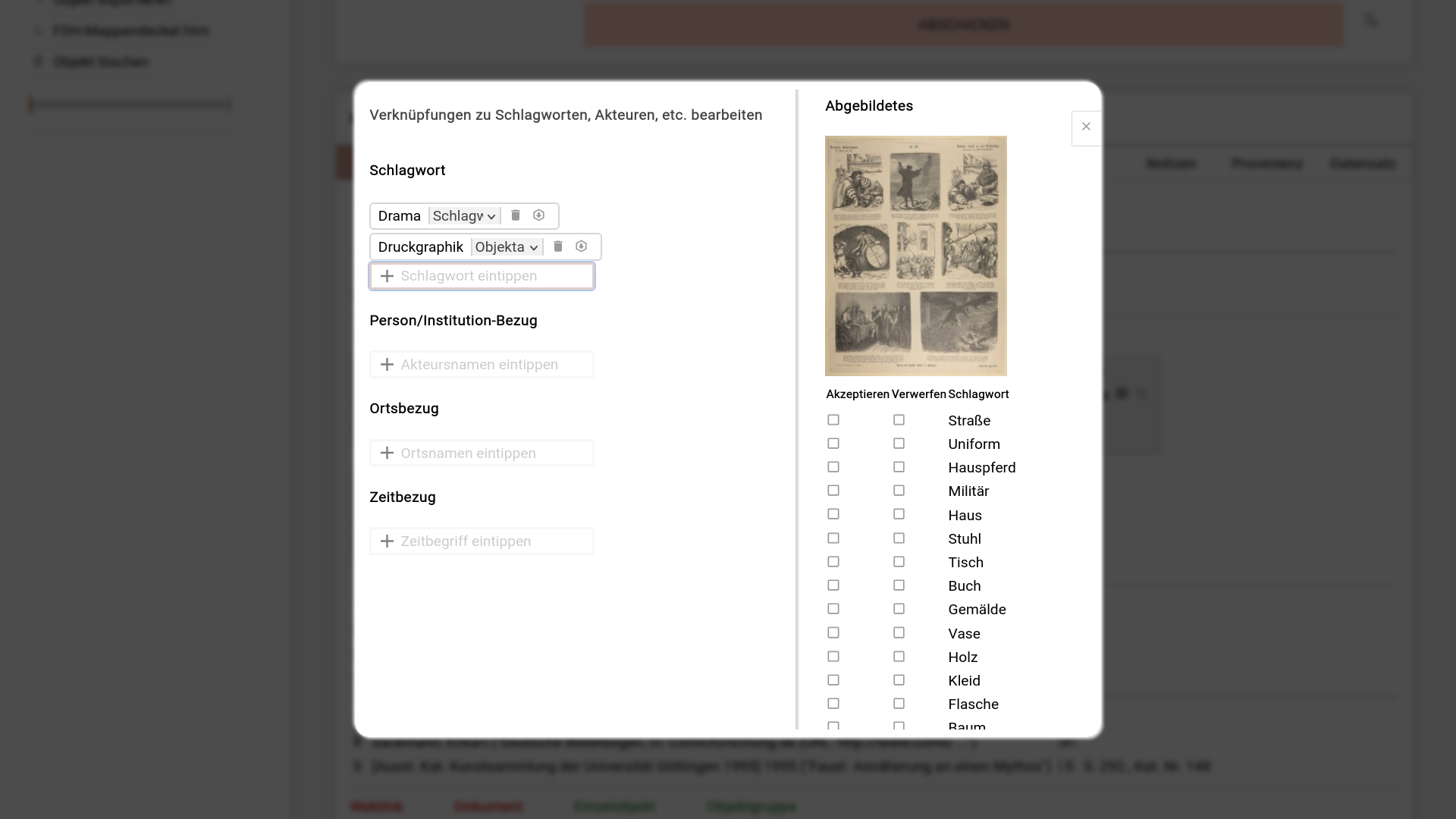
Wird ein neuer Objektdatensatz erstellt, der einer Sammlung mit aktivierter Bilderkennung zugeordnet ist, und zu dem ein Bild vorliegt, so wird dieses später automatisiert mit Vorschlägen aus der Bilderkennung angereichert.
Hierzu wird die reguläre Suchfunktion genutzt, um relevante Objekte und ihre primären Abbildungen zu identifizieren. Diese werden auf lokale Entwicklungs-Maschinen (PC mit Grafikkarte – aber aktuellen, besseren Consumer-Modellen) heruntergeladen und dort ausgewertet. Die so generierten Schlagworte werden auf den Schlagwort-Katalog gemappt und zurück zum Server geschickt.
Ist das einmal geschehen, erscheinen sie als Liste von Checkboxen in der rechten Seitenspalte des Schlagwort-Overlays.
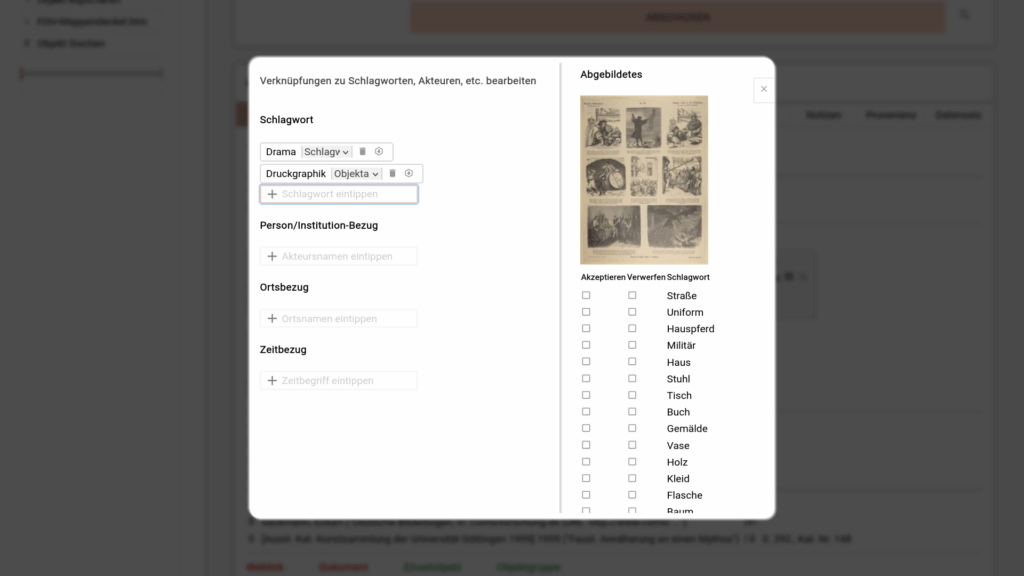
Auswahl des Modells
Dadurch, dass homogenere und stärkere Hardware zur Verfügung steht, können auch größere Modelle eingesetzt werden. Für das neue Feature kommt dabei Joycaption zum Einsatz. Dieses stammt aus dem Umfeld der Open-Source-Bildgenerierung und wurde gezielt für das Beschreiben von Bildern erstellt. Es unterstützt dabei sowohl Prosa- als auch schlagwortartige Beschreibungen.
Ein wichtiger Vorteil des Modells ist, dass es unzensiert ist, während kommerzielle Modelle bei möglicherweise problematischen Inhalten zunehmend eingeschränkt sind. So werden zuverlässig auch z.B. Aktzeichnungen erkannt und beschrieben.
Schlagworte
Joycaption verschlagwortet teils spezifischer als wir das im Rahmen von museum-digital getan hätten. „Schwarzes T-Shirt“ wäre etwa bisher nicht als Schlagwort zugelassen gewesen, ist aber im Sinne der Beschreibung visueller Elemente sinnvoll zuzulassen. „Schwarzes T-Shirt mit einem Ärmel“ wäre allerdings sehr spezifisch. Um die Ausgaben des Modells mit dem Schlagwortkatalog zusammenzubringen haben wir also für ca. 20000 Objekte Beschriftungen erstellt und die daraus resultierenden ca. 6000 Schlagworte auf die bestehenden Vokabulare gemappt.
Wo es bisher keine Entsprechung gab (und der Begriff nicht grundsätzlich unerwünscht ist [„Ohne Menschen“]), wurde ein neues Schlagwort angelegt. Gerade bei Begriffen wie dem „schwarzen T-Shirt“ sind die Begriffe denkbar einfach zu definieren: Ein T-Shirt, das Schwarz gefärbt ist. Entsprechend wurden die so neu eingerichteten Schlagworte automatisiert mit durch das LLM Gemma3 generierte Beschreibungen und deutsche Übersetzungen angereichert, die derzeit gesichtet und bereinigt werden. In diesem Arbeitsschritt werden auch überspezifische Begriffe wie „Schwarzes T-Shirt mit einem Ärmel“ mit unspezifischeren Begriffen („schwarzes T-Shirt“) zusammengeführt, sodass diese unspezifischeren Begriffe stabiler erkannt werden.
Workflows
Durch die nachgelagerte Arbeitsweise – erst Bildupload, dann warten, dann Verschlagwortung- macht der Einsatz der neuen Funktion besonders Sinn, wenn man institutionell einen arbeitsteiligen Workflow hat. Werden Objekte in einem Arbeitsgang von Inventarnummer bis Publikation erfasst, bietet das Tool wahrscheinlich wenig Mehrwert.
API: Wer kann berechnen?
Alle für die Bildklassifikation genutzten Abfragen auf dem Server sind, ebenso wie die Schnittstelle zum Eintragen der Ergebnisse der Klassifikation, auch über die API von musdb verfügbar.
Derzeit werden die API-Abfragen über die administrative Kommandozeile durchgeführt – eine Übersetzung hin zu einer Durchführung mithilfe der Webschnittstelle wäre aber ein leichtes und ist in der bestehenden Implementation schon mitgedacht. Hiermit könnten einzelne Museen die Berechnungen spezifisch für ihre eigenen Objekte durchführen und zeitlich unabhängiger agieren. Bei Interesse: Einfach schreiben. Der Aufwand hielte sich wie gesagt in Grenzen.



Erwähnungen
Nachdem die Posts zu den monatlich neuen Entwicklungen um museum-digital in letzter Zeit ausgeblieben sind, soll die Serie nun fortgeführt werden. Hier also der erste…
The last months have been busy, off and on museum-digital. This is the first of three posts today on recent technical developments around museum-digital to…