Dies ist ein alter Beitrag zu md:term aus meinem persönlichen Blog, der bisher hier nicht auffindbar war. Da mich in letzter Zeit häufiger Fragen zum maschinellen Auslesen der kontrollierten Vokabulare von museum-digital erreichen, veröffentliche ich ihn hier noch einmal. Auch wenn der Beitrag, ursprünglich geschrieben im Januar 2017, schon älter ist, sollte md:term doch im Blog von museum-digital vorgestellt sein.
Seit letzter Woche ist die neue API für die kontrollierten Vokabulare bei Museum-Digital online: md:term. Zusätzlich zur eigentlichen Schnittstelle bietet md:term einen Vokabularbrowser, mit dem Benutzer (ob Programmierer oder nicht) durch die Vokabulare navigieren können.
Kontrollierte Vokabulare bei Museum-Digital
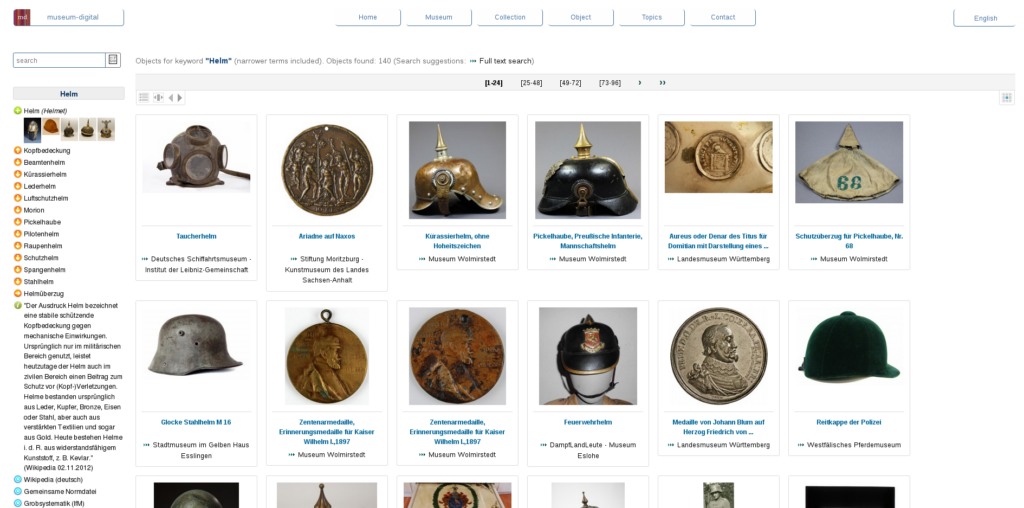
Kontrollierte Vokabulare kommen bei Museum-Digital sowohl bei der Suche als auch bei der Bereitstellung von Kontextdaten zu Museumsobjekten zur Anwendung. Wer z.B. in der deutschlandweiten version von Museum-Digital nach Helm sucht, wird in der Seitenspalte links eine Liste mit unterbegriffen und verwandten Begriffen von Helm finden, die aus den internen kontrollierten Vokabularen gespeist wird. Ist nun ein Objekt ausgewählt, finden sich hinter den Namen von verknüpften Personen und Orten Schalter mit dem Buchstaben i. Klickt der Benutzer auf einen dieser Schalter, werden (so vorhanden) Daten aus den kontrollierten Vokabularen von Museum-Digital angezeigt – Beschreibungen, alternative Namen, Links zu z.B. Wikipedia – oder anhand dieser Daten aus anderen Quellen hinzugeladen – z.B. Karten im Fall eines verknüpften Ortes, auf denen der Ort mithilfe von bei Museum-Digital gespeicherter Koordinaten lokalisiert wird.
Kontrollierte Vokabulare sind also ein wichtiges, wenn auch relativ leicht zu übersehendes Element von Museum-Digital. Entsprechend wird viel Arbeit in die Moderation der Vokabulare gesteckt.
Während jeder Eingebende neue Begriffe hinzufügen kann, werden diese von einer ausgewählten Gruppe von Leuten moderiert, angereichert oder ggfs. mit existierenden Begriffseinträgen zusammengeführt.
Mittlerweile sind alleine in den deutschsprachigen kontrollierten Vokabularen – unterteilt in Personen, Orte, Zeiten und Schlagworte – über 55000 moderierte Begriffe vorhanden, die sicherlich nicht nur für die Verwendung bei Museum-Digital nützlich sein können. Das Schreiben einer öffentlichen und generell nutzbaren Schnittstelle ist eine logische Konsequenz hiervon.
md:term
Daten aus den kontrollierten Vokabularen sind bei md:term in bisher drei Formaten abrufbar: Einer im Webbrowser betrachtbaren und navigierbaren HTML-Version, in JSON und SKOS, die als leicht maschinenlesbare Formate die Benutzung durch externe Programierer erleichtern.
Ein wichtiger Teil von md:term ist hierbei die Umbenennung von Variablen. Während museum-digital ursprünglich in Deutschland entstanden ist und in der Datenbank entsprechend deutsche Namen verwendet werden, wird es mittlerweile beispielsweise auch in Ungarn eingesetzt. Damit die Benutzung der kontrollierten Vokabulare auch durch nicht deutschsprachige Programmierer möglich ist, werden die Variablennamen mit englischen Entsprechungen überschrieben.
Ebenfalls auf internationale Benutzbarkeit ausgerichtet, bietet die HTML-Version deutsche und englische Übersetzungen von feststehenden (also nicht nur zu einem einzelnen Datensatz gehörenden) Texten, z.B. Überschriften und der Navigation. Dies kann in Zukunft leicht um zusätzliche Sprachen erweitert werden.
Daten von md:term abfragen
Zur Abfrage von md:term in JSON und SKOS muss die ID eines Eintrags in der entsprechenden Datenbank bekannt sein. Ist dies der Fall, wird eine Abfrage in der URL nach dem Format https://term.museum-digital.de/Name der Vokabularversion (z.B. md-de)/Typ des Eintrages/ID/format durchgeführt. Zum Beispiel:
$ curl https://term.museum-digital.de/md-de/place/13384/json
{
"id": "13384",<br>"name": "Abtstra\u00dfe (Brandenburg an der Havel)",
"class": "Stra\u00dfe",
"tgn": "",
"geonames": "",
"latitude": "52.406989561274",
"longitude": "12.564392566637",
"zoom": "16",
"note": "Stra\u00dfe in Brandenburg an der Havel",
"synonyms": [],
"references": [],
"broader": {
"": [{
"name": "Brandenburg an der Havel",
"broader_id": "246"
}]
},
"narrower": []
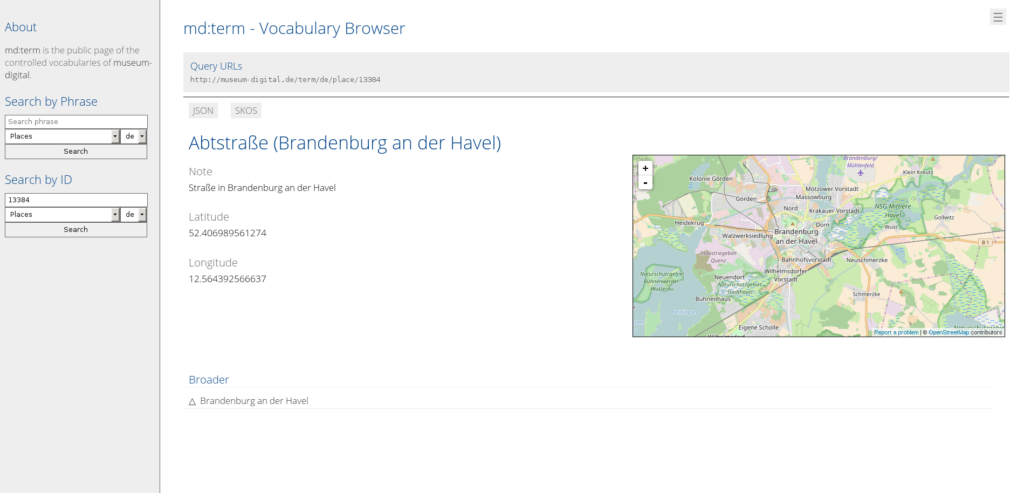
}Aus den Abfrageergebnissen kann man IDs für weitere Abfragen finden, der Ort im Beispiel, die Abtstraße (Brandenburg an der Havel) mit der ID 13384 ist Brandenburg an der Havel mit der ID 246 untergeordnet.
Eine Suchfunktion ist bisher nur in der HTML-Ausgabe vorhanden. Gibt es ein im Namen perfekt übereinstimmendes Suchergebnis oder nur ein einziges bei einer loseren Entsprechung, wird direkt auf den entsprechenden Eintrag umgeleitet. Gibt es zwei oder mehr, so werden dem Benutzer die möglichen Suchergebnisse mit Titel und, so vorhanden, Beschreibung aufgelistet.
Ist man so zum gewünschten Eintrag gelangt, ist über der Ausspielung der Daten ein Feld mit der Abfrage-URL und – direkt darunter – Links zum Eintrag in alternativen Formaten zu finden.