Um die Vorzüge von Datenbanksystemen voll ausnutzen zu können, braucht es klar referenzierbare Einträge. Ein Fantasie-Beispiel: Ein Objekt wurde 1620 hergestellt von Max Mustermann, ein anderes hergestellt von Max Mustermann im Jahr 1950. Sicherlich wird das nicht derselbe Max Mustermann gewesen sein. Um zwischen den beiden Personen unterscheiden zu können, werden diese in einer Datenbank als eigener, selbstständiger Datensatz erfasst, der wiederum mit anderen Datentypen oder externen Datenbanken verknüpft werden kann.
Einerseits ermöglicht das eben die Unterscheidung zwischen verschiedenen, zuerst einmal ähnlich aussehenden Einträgen, und macht wirklich saubere verknüpfen und suchen nach z.B. Personen erst möglich. Andererseits bedeutet es eine Mehrarbeit und manchmal einen Perspektivwechsel.
museum-digital vereinfacht die Verknüpfung mit Personen durch die Benutzung eines von allen Teilnehmenden gemeinsam genutzten Vokabulars für Personen. Ist eine Personen schon aus einem anderen Museum bekannt, muss sie im eigenen Haus nicht neu erfasst werden. Im Idealfall ist der Eintrag auch schon mit z.B. der Wikipedia oder der Gemeinsamen Normdatei verknüpft. Damit die gemeinsame Benutzung der Personenliste aber funktioniert, braucht es eine minimale Datenqualität: Personen müssen mit Lebensdaten und einer Beschreibung von mindestens zehn Buchstaben erfasst werden.
Damit erzwingt das System zumindest bei der Ersteingabe von Personeneinträgen eine Recherche, die andernorts gerne vergessen wird – auch wenn sie dort ebenso sinnvoll wäre, gegeben, dass die Daten irgendwann in einen weiteren Kontext gesetzt werden sollen. Arbeit macht es natürlich trotzdem.
Unvollständig sind die automatischen Qualitätsprüfungen naturgemäß ebenfalls. Die Überprüfung, ob eine Beschreibung von 10 Buchstaben vorhanden ist, ist einfach – aber eine Überprüfung, ob es sich bei der Beschreibung um einen Blindtext handelt ist schwer.
Um also allen die Arbeit zu vereinfachen, den direkt eingebenden genauso wie der „Normdatenredaktion“, haben wir in den letzten Wochen Schritte unternommen, um die Eingabe von Personeneinträgen einfacher zu machen, und gleichzeitig das Erreichen einer höheren Datenqualität zu erleichtern.
Schnelleres erscheinen der Personenliste
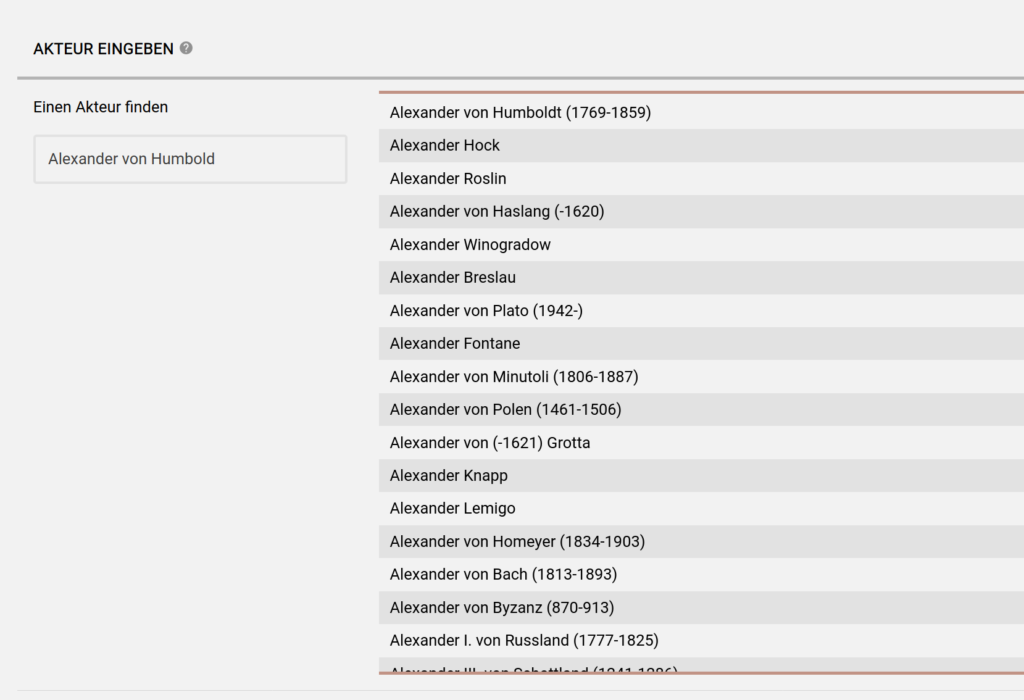
Möchte man in musdb eine Person mit einem Objekt verknüpfen, wird einem zuerst eine durchsuchbare Liste der verfügbaren, dem eingegebenen Namensbestandteil entsprechenden Personeneinträge angezeigt. Leider war die Generierung der Liste lange Zeit eine der langsameren Funktionen im System. Je langsamer die Liste erscheint, desto attraktiver ist natürlich das Anlegen eines neuen Eintrags für eigentlich schon erfasste Personen, auch wenn so für die Redaktion Mehrarbeit entsteht.
Mit einem Neuschreiben der Listengenerierung konnten wir die Anzahl der benötigten Datenbankabfragen wesentlich generieren und die Generierungszeit der Liste von über 100 Millisekunden auf knapp vier Millisekunden reduzieren (den Benchmarks nach).
Besseres Erkennung von Vornamen und Nachnamen
Ist eine zu verknüpfende Person nicht aufgelistet, kann man Sie mit dem Drücken der Return-Taste neu einfügen und wird zuerst gefragt, ob es sich um eine Person, eine Institution, oder eine Sagengestalt handelt. Handelt es sich um eine Person, wird der angegebene Name in Vorname und Nachname aufgespalten.
Bisher wurde der eingegebene Name nach einer einfach Logik aufgespalten: Das letzte „Wort“ des Namens (die letzte durch ein Leerzeichen abgetrennte Zeichenkette) wurde zum Nachnamen erklärt, der Rest zum Vornamen. „Luz Magsaysay“ wäre also zu „Vorname: Luz„, „Nachname: Magsaysay“ übersetzt. Hätte ein Benutzer versucht, „Magsaysay, Luz“ einzugeben, wäre dies vom System als „Vorname: Magsaysay,„, „Nachname: Luz“ interpretiert worden. Ein ähnliches Problem stellt sich bei anderen Sprachen: In Ungarisch werden Namen Prinzipiell in der Reihenfolge <Nachname> <Vorname> genannt.
Seit dieser Woche geschieht die Aufspaltung von Personennamen mit einer ausgeklügelteren Logik. Zuerst wird geprüft, ob der Benutzer eine Sprache wie z.B. Ungarisch benutzt, in der der Nachname zuerst genannt wird. In diesem Fall wird das erste „Wort“ des eingegebenen Namens als Nachname verstanden, der Rest als Vornamen.
Benutzt der Benutzer musdb beispielsweise in Deutsch, wird überprüft, ob das erste „Wort“ mit einem Komma beendet wird. Ist dem der Fall wird das erste „Wort“ als Nachname interpretiert (nach Entfernen des Kommas), der Rest als Vorname.
Wird das Programm in Deutsch verwendet, und findet sich kein Komma am Ende des ersten „Wortes“ gilt weiterhin die herkömmliche Logik: Das letzte „Wort“ wird als Nachname genutzt.
Beschreibung? Wikipedia-Link!
Viele Personen sind bereits in anderen Repositorien erfasst – besonders Wikidata und den verschiedenen Sprachversionen der Wikipedia. Eine Funktion zum automatischen Laden von Informationen zum gebenen Eintrag aus Wikidata heraus gab es seit langem im Bearbeitungstool für die Vokabulare von museum-digital, nodac. Seit einigen Wochen können Eingebende in musdb diese Funktion selbst nutzen: Es gibt einen neuen Eingabeschlitz „Wikipedia-URL“ auf der Personen-Eingabeseite.
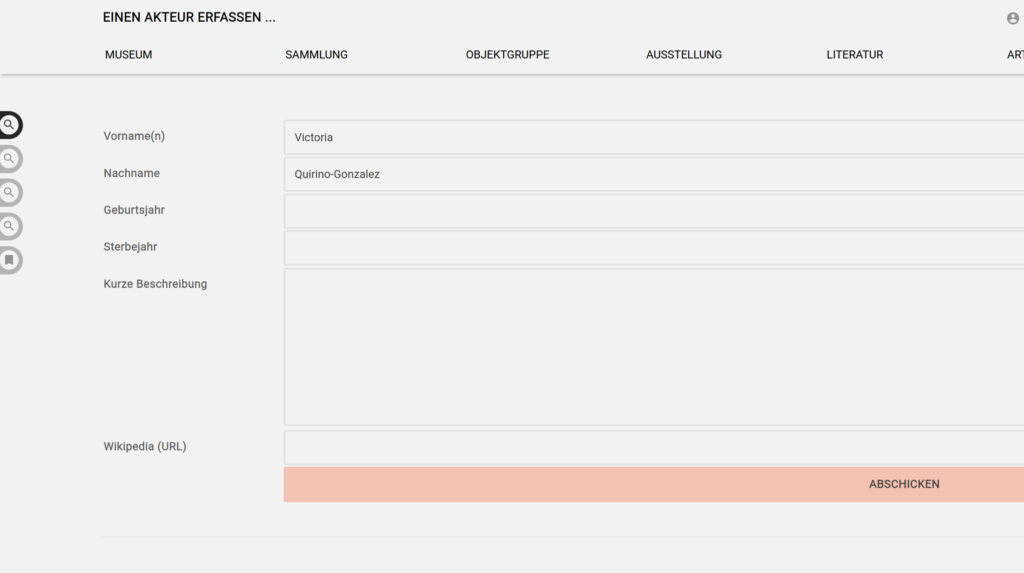
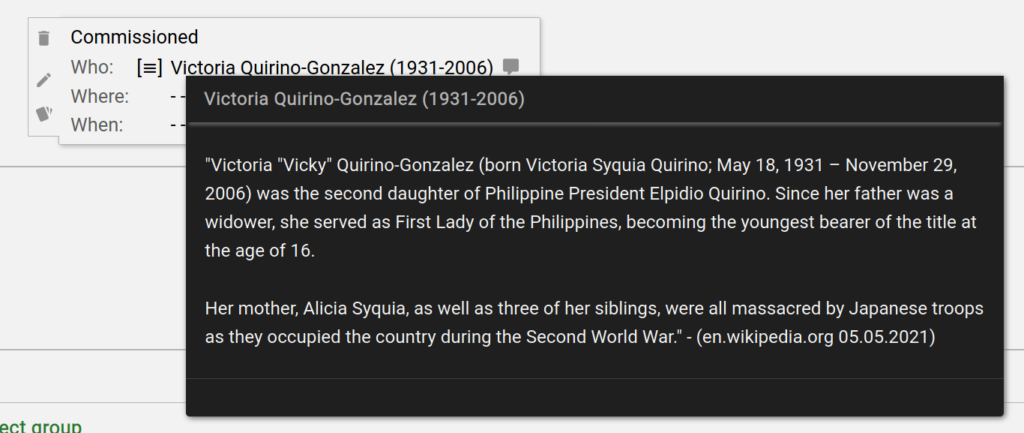
Ist dieser mit einer URL einer passenden Wikipedia oder Wikidata-Seite ausgefüllt, muss keine Personenbeschreibung mehr eingegeben werden. Stattdessen wird im Hintergrund die Wikidata-ID der Person aus der verlinkten Seite ausgelesen. Auf Basis dieser ID kann der neu angelegte Datensatz dann gleich tiefergehend angereichert werden: Lebensdaten und Verknüpfungen zu anderen Normdaten-Repositorien werden von Wikidata übernommen, und die Kurzbeschreibungstexte in den vorhandenen Übersetzungen aus den verlinkten Wikipedia-Instanzen kopiert.
Eine kleine Hilfe beim finden der passenden URLs können vielleicht neue Links in der Toolbar geben: Mit diesen kann eine schnelle Suche in Wikidata und VIAF (und, falls der User das Programm in Deutsch benutzt, der deutschen Wikipedia und der GND), vorgenommen werden.
Insgesamt hoffen wir, dass sich so die Qualität der Daten schon bei der Eingabe verbessern lässt, und der Eingabeprozess trotzdem schneller und komfortabler wird.