Eine der großen Stärken von musdb, dem Eingabe- und Inventarisierungstool von museum-digital, ist seit langer Zeit seine Fähigkeit, auf Inkonsistenzen und unvollständige Eingaben hinzuweisen. Mit dem „PuQi“ (Publikations-Qualitäts-Index) wird darauf hingewiesen, wo Datensätze vervollständigt werden können, wo ein Beschreibungstext für die Publikation zu lang oder zu kurz ist etc. Der „Plausi“ weist auf potenziell unlogische Bezüge hin: Wurde ein Gemälde von Caspar David Friedrich (geboren 1774) gemalt, kann es nicht vor 1774 versendet worden sein. Beide Tools machen die Qualität der Datensätze – ein Stück weit – quantifizierbar und suchbar. Aber sie sind passiv – sie helfen Probleme zu identifizieren, die dann behoben werden können, aber sie helfen nicht bei der konkreten Lösung der Probleme.
Vorschläge machte musdb andererseits bisher vor allem auf Basis der zuletzt getätigten Eingaben: Soll etwa ein Objekt etwa verschlagwortet werden, werden in einer Seitenspalte die zuletzt benutzten Schlagworte angezeigt. Die Annahme, dass üblicherweise ähnliche Objekte nacheinander eingegeben werden, ist zwar naheliegend und meist richtig, aber es gibt viele weitere gute Optionen, um automatisch Vorschläge anzubieten.
Mit dem Entwicklungen der letzten beiden Monate sind wir in der Entwicklung einen großen paradigmatischen Schritt gegangen: Das System erkennt – bei einer gegebenen Liste von Fällen – behebbare Unvollständigkeiten, und schlägt zusammen mit der Nachricht direkt eine Lösung vor.
Verbesserungsvorschläge
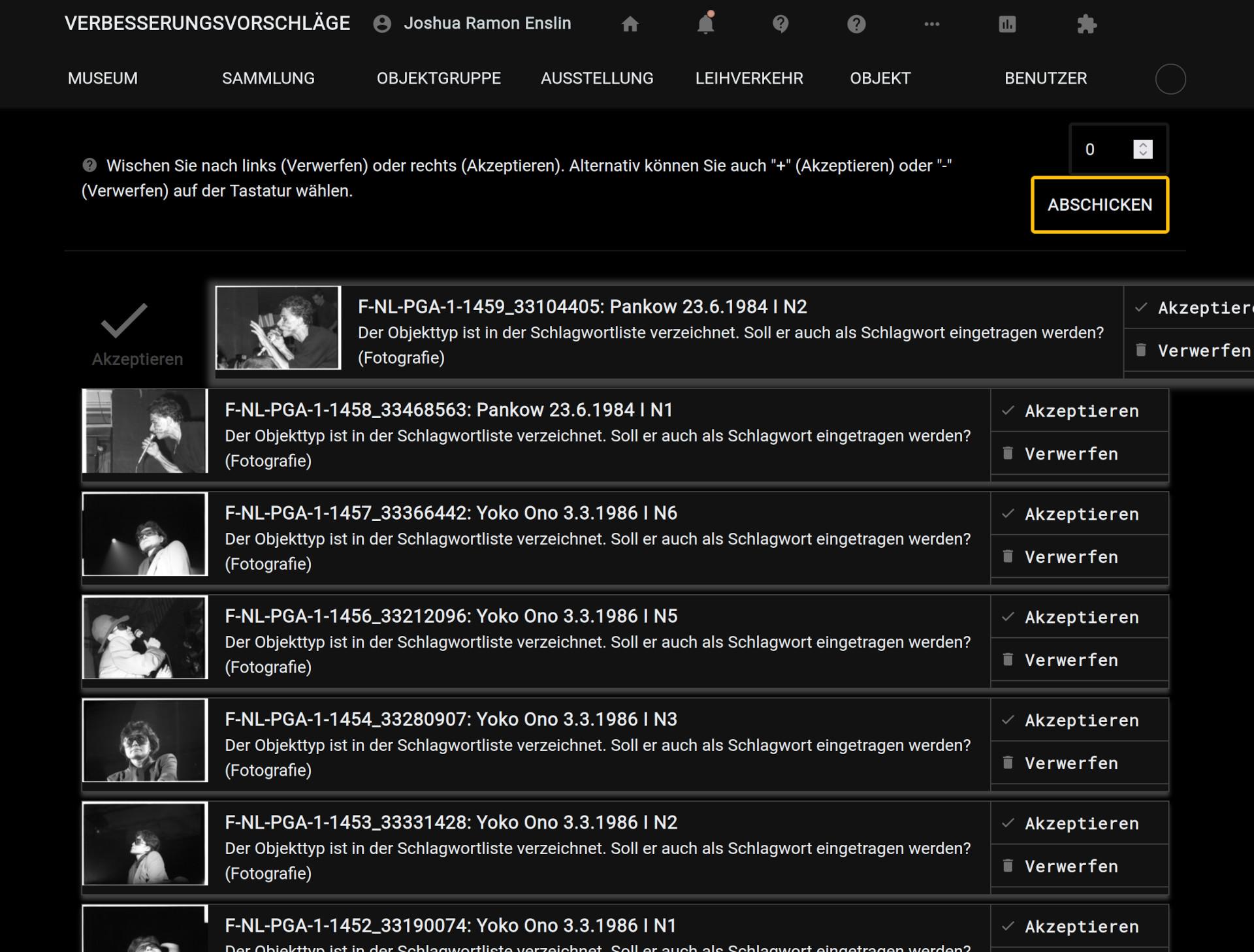
Die Verbesserungsvorschläge für Objekte sind auf zweierlei Wegen erreichbar: Gibt es einen Vorschlag zu einem Objekt, das man gerade bearbeitet, erscheint der Hinweis darauf aber natürlich auch direkt beim Objekt (direkt neben der Überschrift). Spannender ist aber die allgemeine Liste für die schnelle Abarbeitung der Vorschläge, die jetzt über die Navigation in musdb erreicht werden kann.
Die so erreichte Liste ist optimiert, um ein Abarbeiten der Vorschläge so niedrigschwellig wie möglich zu ermöglichen: Jeder Vorschlag bildet eine Zeile und kann akzeptiert (und ausgeführt) oder verworfen werden. Um zu akzeptieren oder zu verwerfen, kann man entweder wie gehabt die entsprechenden Buttons klicken oder man wischt den Eintrag – grob analog zu z.B. Tinder – nach links (verwerfen) oder rechts (akzeptieren). Ist kein Touchscreen in Reichweite kann der oberste Eintrag der Liste über die Tasten „-“ und „+“ verworfen bzw. akzeptiert werden.
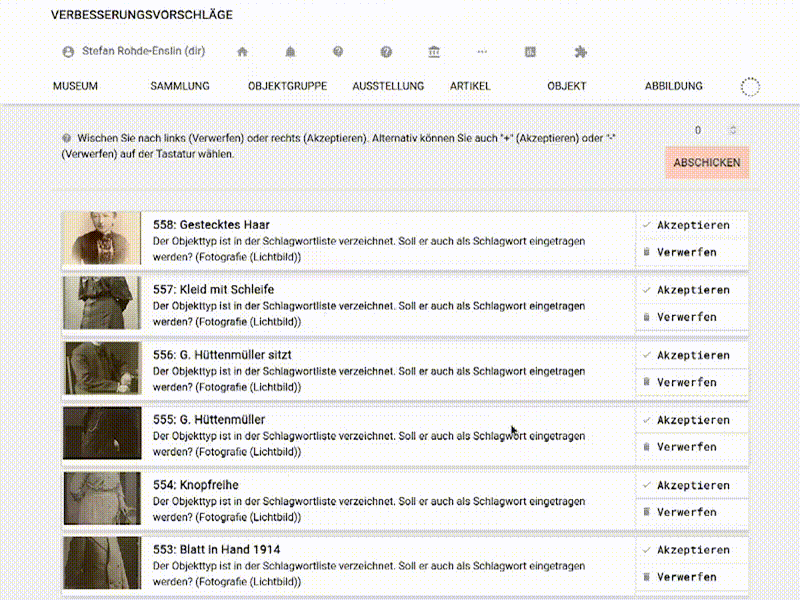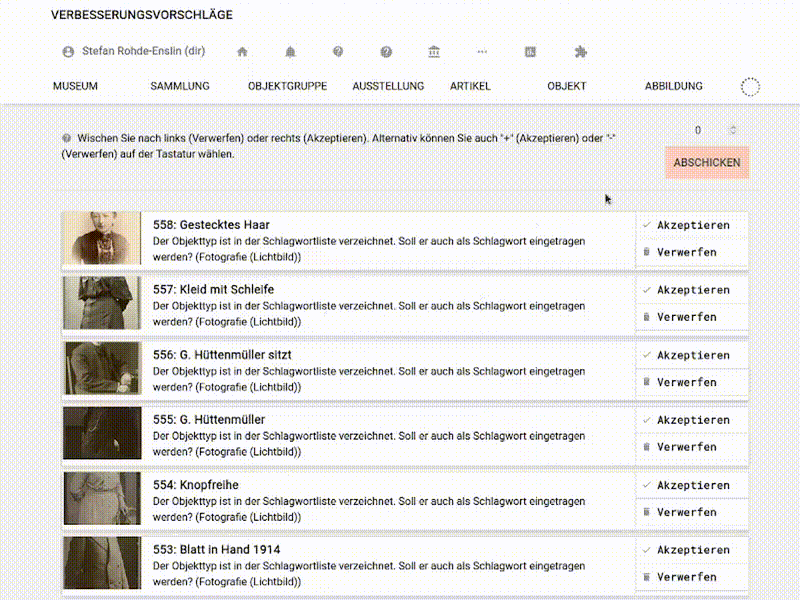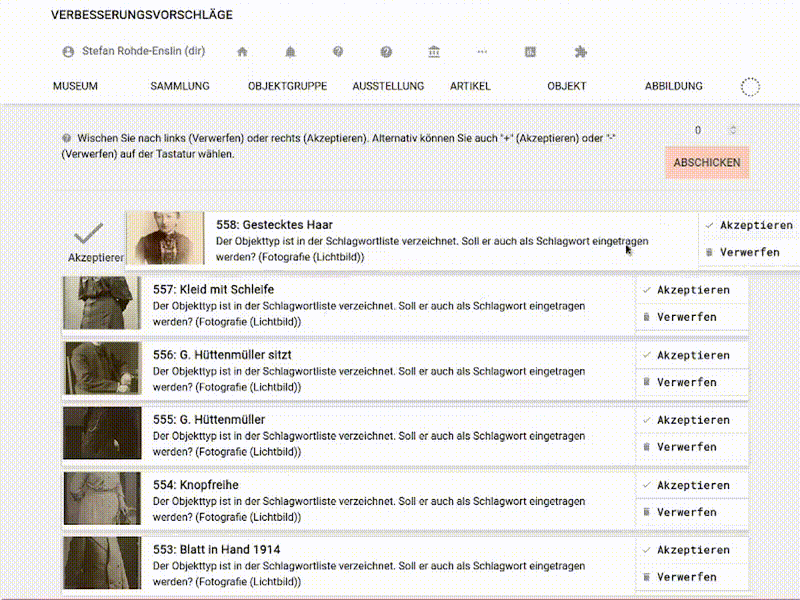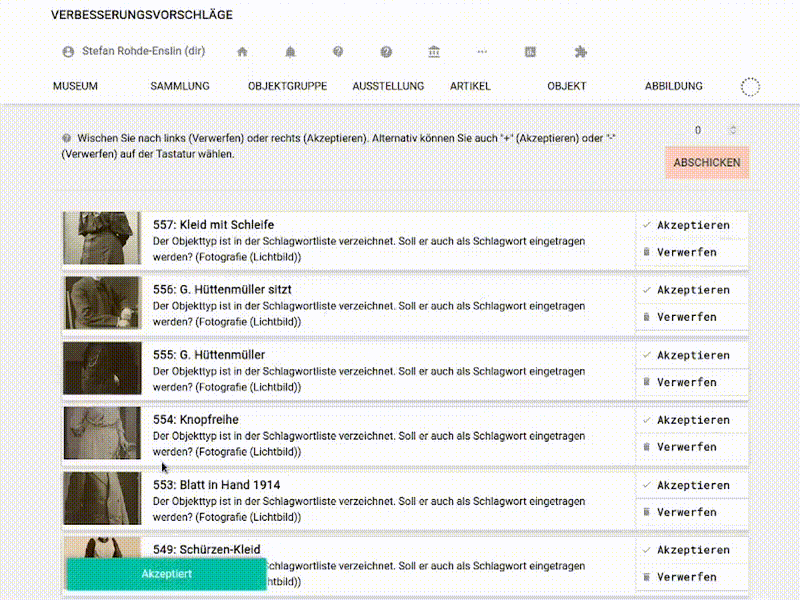
Und was schlägt musdb da vor?
Verbesserungsvorschläge die so angeboten werden sollen müssen natürlich mindestens fast sicher sein, daher deckt die Funktion bisher nur eine kleine Anzahl an Fällen ab:
- Objektart als Schlagwort
Das Feld für Objektarten ist bei museum-digital nicht kontrolliert, einerseits weil die Kategorisierung über Schlagworte breitere Suchmöglichkeiten bietet, andererseits weil viele Objekte bei museum-digital über Importe erfasst werden und etwaigen Vorgaben sicher widersprechen würden. Beim Neu-Eingeben ist die Benutzung von erkennbaren Objektarten aus der Schlagwortliste aber unbedingt sinnvoll – und genauso das Verschlagworten des Objektes mit seiner Objektart. Ist ein Objekt z.B. ein Stein, schlägt musdb vor, auch das Schlagwort „Stein“ mit dem Objekt zu verknüpfen. - Dargestellte Person in Selbstportraits
Ein immer wieder auftretendes Problem, ist das die auf einem Gemälde oder einer Fotografie abgebildete Person nicht gesondert als „Dargestellte Person“ erfasst wird. Dabei sind gerade diese Daten besonders interessant für interessante Weiterentwicklungen (von Visualisierungen bis zur automatierten Bilderkennung)!
Ein Sonderfall, in dem die Person implizit bekannt ist, sind Selbstportraits. Ist das Objekt ein Selbstporträt, und ist ein Maler oder Fotograf bekannt, schlägt musdb vor, dieselbe Person auch als dargestellte Person zu verknüpfen. - Fehlende Sprach-Angaben bei Schriftwerken
Ein recht neues Eingabefeld bei museum-digital, aber ein umso gebräuchlicheres im Umgang mit Texten ist die Sprache: „Ist der vorliegende Text in Deutsch oder Russisch verfasst?“ Die Erfassung der Sprache macht bei allen Text-Objekten unbedingt Sinn, ist aber natürlich bei anderen Objekttypen kontraproduktiv. Eine Steinaxt hat – natürlich – keine Sprache.
Deshalb prüft musdb erst, ob ein Objekt verfasst wurde (also ein Ereignis „verfasst“ verknüpft ist). Ist das der Fall, wird es sich wohl um ein Objekt mit Text handeln – und musdb kann die Sprache, in der der oder die Eingebende das Programm benutzt, als Sprache des Textes vorschlagen. Achtung: Dieser Vorschlagstyp ist der uneindeutigste der bisher vorhandenen. - Präzisierung von Ereignisangaben
Viele vorhandene Ereignisangaben lassen sich naheliegend auf Basis der Objektart spezifizieren: Wurde ein Gemälde „hergestellt“, oder wurde es nicht eher „gemalt“? Wurde ein Foto „hergestellt“? Wahrscheinlich wurde es eher „aufgenommen“.
Ist ein solcher Fall identifizierbar, schlägt musdb vor, die Angabe zu spezifizieren.
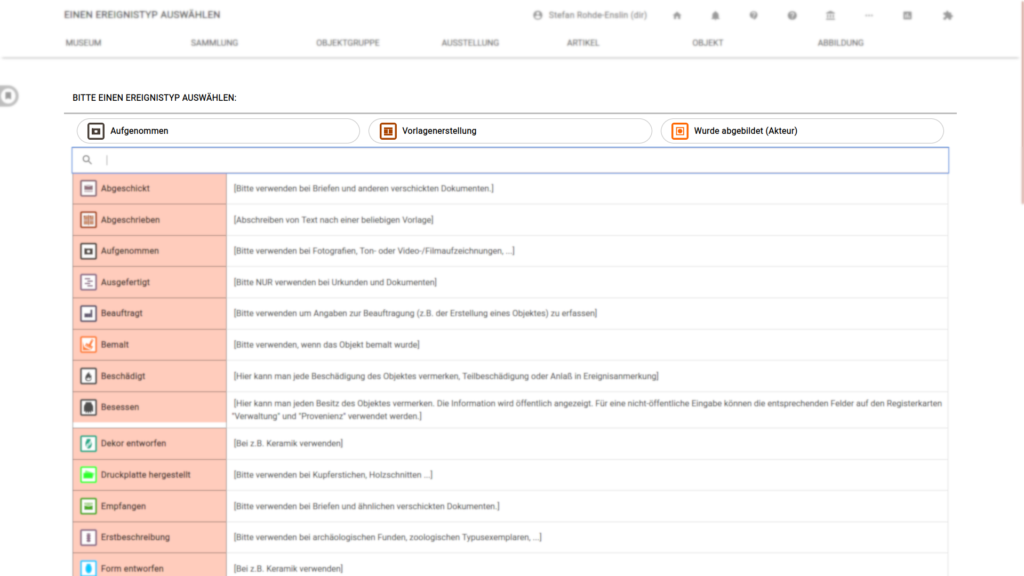
Vorgeschlagene Ereignistypen nach Objektart
Mit verschiedenen Arten von Objekten passieren verschiedene Ereignisse. Gemälde werden gemalt, haben aber bestimmt nicht gelebt. Amoniten haben gelebt und wurden (wenn sie heute im Museum sind) zu irgendeinem Zeitpunkt gefunden, wurden aber bestimmt nicht verfasst.
Auch wenn das Feld „Objektart“ bei museum-digital nicht kontrolliert wird, können wir doch mit vielen der gebenen Objektarten umgehen, indem wir die Hierarchie des Schlagwortkatalogs zu Hilfe nehmen. Ist als Objektart „Carte-de-Visite“ angegeben, kann derselbe Begriff (auf Basis des gleichen Namens) im Schlagwortkatalog von museum-digital gefunden werden. Das Schlagwort „Carte-de-Visite“ ist dem Begriff „Fotografie (Lichtbild)“ untergeordnet – und so lässt sich aus den Daten schließen, dass es sich beim Objekt um eine Fotografie handelt.
Weil Fotografien nun eben vor allem „Aufgenommen“ werden, für sie „Vorlagen erstellt“ werden, und sie oft Orte oder Personen abbilden, lässt sich dieses Wissen nutzen, um die naheliegenden Ereignistypen ganz oben in der Liste der Ereignistypen (beim Anlgen eines neuen Ereignisses) vorzuschlagen. So sind sie leichter erreichbar und können hoffentlich zu einer schnelleren – aber genauso richtigen – Erfassung beitragen.
Bilderkennung
Nachdem die logischen Schlüsse, die sich aus dem Zusammenspiel von kontrollierten Vokabularen und Objektdaten schließen lassen nun wesentlich weitergehend auch in (Verbesserungs-)Vorschlägen niederschlagen, stellt sich die Frage, was der nächste Schritt für bessere Vorschläge an mehr Stellen ist. Naheliegend, weil zunehmend gut erforscht und zunehmend auch im alltäglichen Einsatz ist dabei Bilderkennung (bzw. Bild-Klassifikation). Und auch im Museumssektor ist sie hin und wieder pressewirksam für die Verschlagwortung von Bildern und Objekten eingesetzt worden. Warum dann also nicht bei museum-digital?
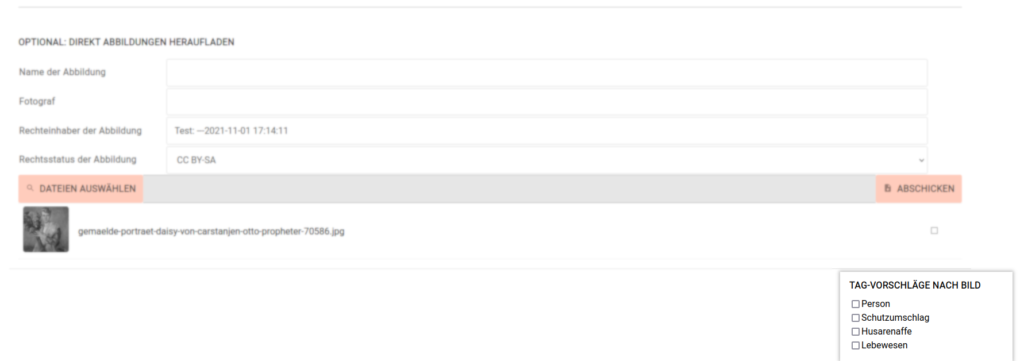
Um automatische Bilderkennung sinnvoll einsetzen zu können, müssen allerdings zuerst einmal Bilder vorhanden sein, die dann im Folgenden klassifiziert werden können. Deshalb ermöglicht die Objekt-Eingabeseite jetzt direkt das Hochladen von Bildern zum Objekt.
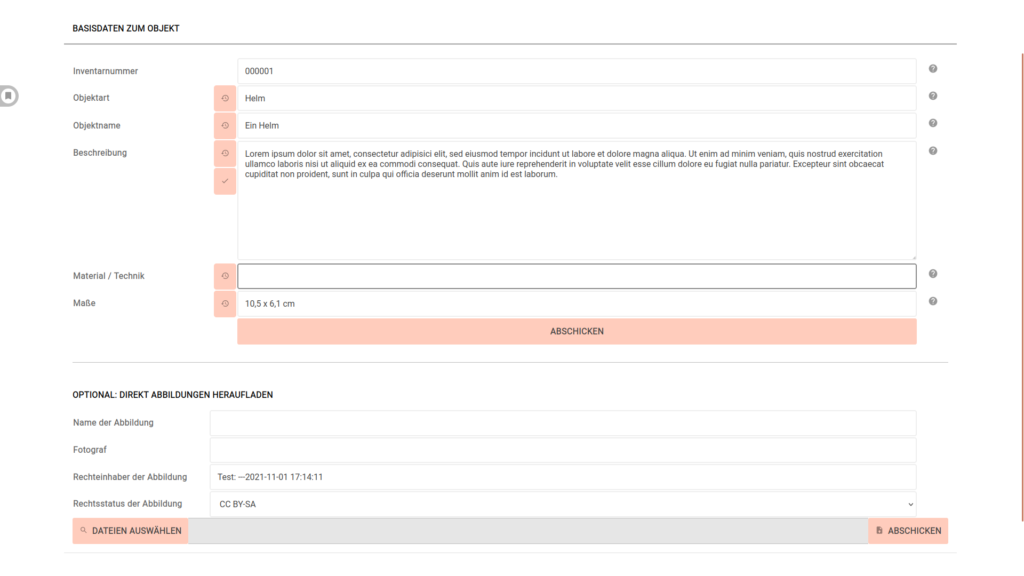
Wird an dieser Stelle ein Objektbild angefügt, wird gleich ein Versuch Schlagworte vorzuschlagen, unternommen. Bisher sind die Resultate meist noch nicht gut. Aber so steht zumindest einmal die richtige Architektur, um Bilder, künstliche Intelligenz und ihr Zusammenwirken bei Erleichterung der Inventarisierung wesentlich mehr (oder überhaupt erst einmal) einzusetzen.
Bisher werden zur Bild-Klassifikation generische Modelle für browserbasierte Bilderkennung verwendet (mobilenet und coco-ssd). Alleine ein spezifisches Weiter-Training der Modelle auf Basis der bei museum-digital vorhandenen Daten sollte schon wesentliche Fortschritte mit sich bringen.