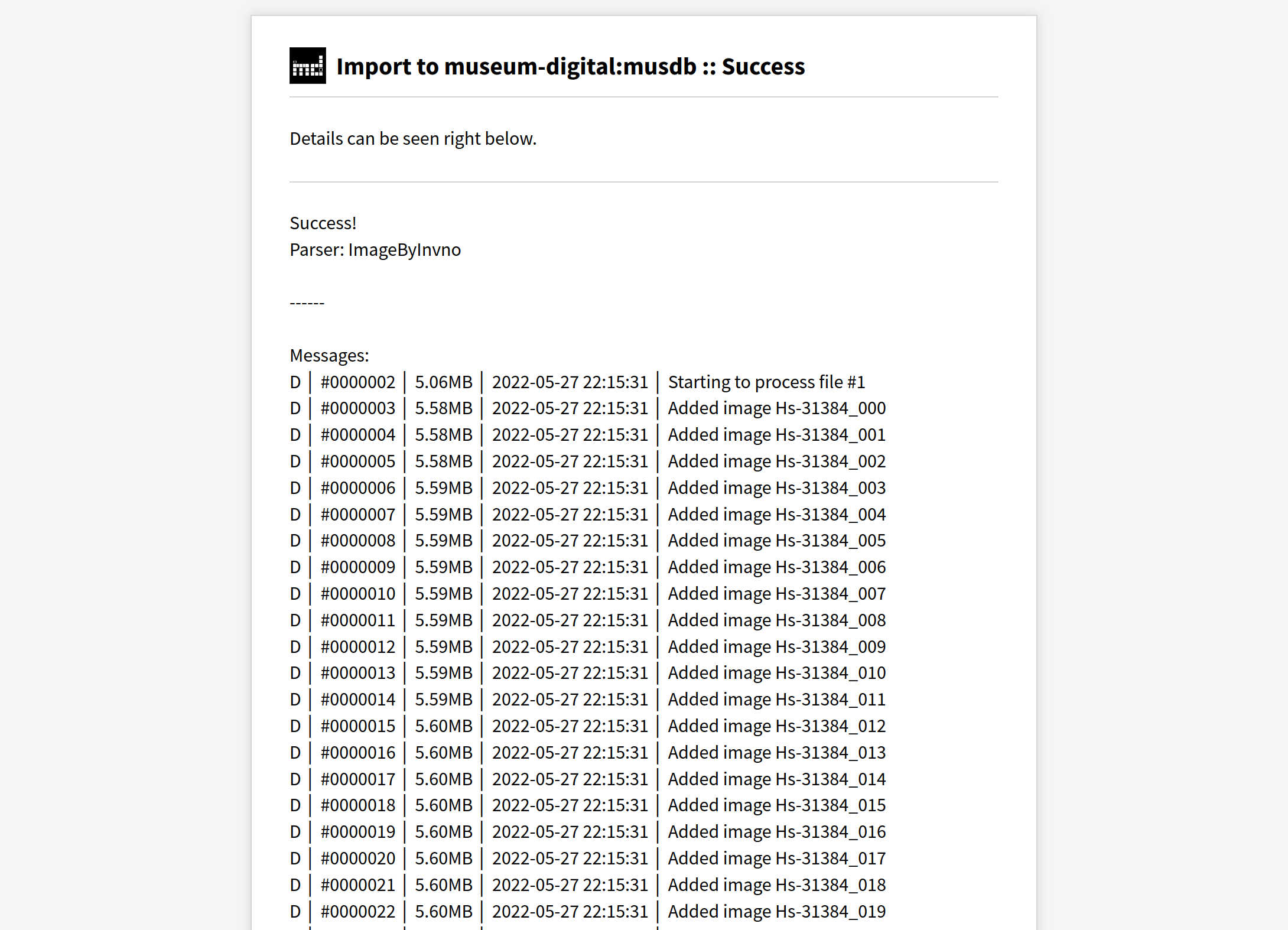
Bis letzten Monat war der Ablauf eines Importes bei museum-digital immer dadurch beschränkt, dass ein Mitglied des Technik-Teams involviert sein musste. Das war schon alleine deshalb der Fall, weil es bis dahin keine Option für User gab, die zu importierenden Daten auf den Server zu laden. Nach vielen Jahren konnten wir die Import-Funktion jetzt endlich auch für das eigenständige Durchführen von Importen durch Benutzer, die einen Zugang zu musdb haben, öffnen.
Die wichtigste Bedingung dafür war wie schon beschrieben, dass eine Möglichkeit geschaffen werden musste, die Importdaten überhaupt hochzuladen. Dies kann über eine neu eingerichtete WebDAV-Schnittstelle getan werden. WebDAV ist ein Protokoll, das grob analog zu FTP benutzt werden kann, und zum Beispiel auch für die Synchronisierung zwischen einem Rechner und einem Cloudspeicher wie Google Drive oder Nextcloud zum Einsatz kommt. Es hat den Vorteil, dass es auf HTTP (also das Standard-Protokoll, über das Webseiten aufgerufen werden) aufsetzt, und so auch in größeren Institutionen oder in solchen, deren IT von der jeweiligen Kommune gemanaged wird, nicht von Firewalls blockiert werden sollte. Zusätzlich gibt es selbst im Windows Explorer die Möglichkeit, sich mit WebDAV-Netzwerklaufwerken zu verbinden (siehe z.B. hier für eine Anleitung). Ein Upload sollte also protokollbedingt kein Problem darstellen.
Wie importieren?
Zugangsdaten zur WebDAV-Schnittstelle kann man in musdb bei den Einstellungen für das eigene Benutzerkonto erhalten (oben in der Navigation auf den eigenen Namen klicken, dann im Menü auf „Kontoeinstellungen“). Unterhalb der grundlegenden Tabelle für Logindaten findet sich hier ein neuer Reiter „WebDAV“. Öffnet man diesen „Reiter“ erhält man eine kurze Erläuterung auf Englisch und einen Button „Generate WebDAV password“. Klickt man diesen, werden die Zugangsdaten mit einem automatisch generierten Password angezeigt. Das Password sollte gut gespeichert werden, weil es auf dem Server nur in gehashter – also gezielt nicht zurückberechenbarer – Form vorliegt.
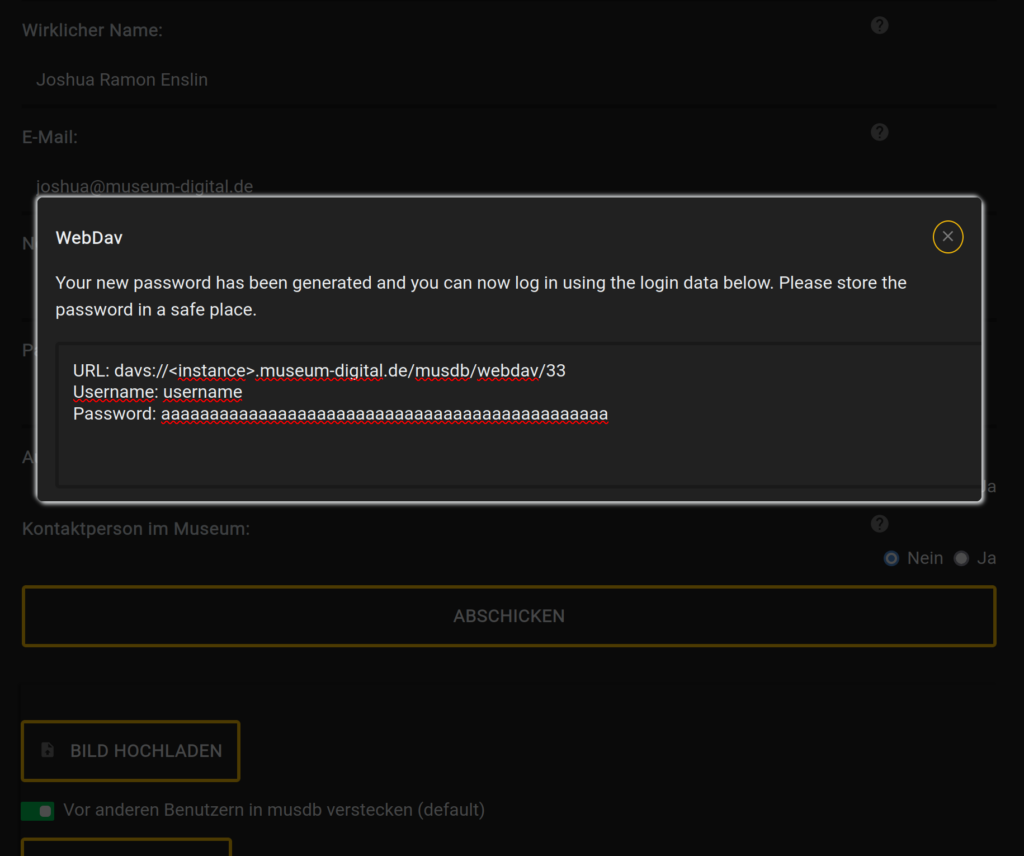
Mit diesen Logindaten kann man sich über einen WebDAV-Client einloggen. Möchte man nur Ausprobieren, wie das Ganze funktioniert, bietet sich hier der jeweilige Dateimanager (also z.B. der Windows Explorer) an. Möchte man öfter selbst importieren, lohnt sich spezialisiertere Software wie z.B. WinSCP. Je nach Software muss die Angabe des Protokolls von davs:// zu https:// geändert werden.
Wichtig ist dabei anzumerken, dass die generierten Zugangsdaten immer nur Zugang zur Schnittstelle für die eigene „Heimat-Institution“ geben. Für die meisten Benutzer ist das unproblematisch, aber für Benutzer, die Zugriff auf die Daten mehrerer Museen haben, bedeutet das, dass sie nur für das Haus, dem ihr Benutzerkonto primär zugeordnet ist, Importe durchführen können.
Angekommen auf dem Netzwerklaufwerk: Importdaten hochladen
Hat man sich mit einem WebDAV-Client und mit den eben bezogenen Logindaten zum Server verbunden, sieht man zwei Dateien und zwei Ordner.
.
├── import_config.sample.txt
├── IMPORT_IMG
├── IMPORT_XML
└── README.mdDer Zweck der Datei README.md sollte offensichtlich sein. Hier werden noch einmal die Ordnerstruktur und die folgenden Schritte beschrieben.
Importdaten hochladen
Die Ordner IMPORT_IMG und IMPORT_XML sind die Ordner, in die die zu importierenden Daten hochgeladen werden können. Das geschieht, wie schon von der Ordnerstruktur angedeutet, getrennt nach Dateitypen, wobei die Metadaten in den Ordner IMPORT_XML geladen werden, und Mediendateien in den Ordner IMPORT_IMG hochgeladen werden.
Datei ist zweierlei zu beachten: Einerseits sollte man sich von den Benennungen nicht verwirren lassen. Der Ordner IMPORT_XML ist für alle Metadaten-Dateien gut, sie müssen nicht unbedingt im XML-Format vorliegen. Andererseits sollten in diesen Ordnern keine weiteren Unterordner erstellt werden. Fast alle Import-Scripte („Parser“) verlangen, dass die Daten direkt in den jeweiligen Ordnern liegen.
Die zu importierenden Daten werden nun also in die beiden Ordner hochgeladen.
Den Import konfigurieren
Im letzten Schritt muss dem Server mitgeteilt werden, was für eine Art von Daten dort importiert werden soll. Und, dass der Import überhaupt stattfinden soll. Das geschieht mit der Datei import_config.sample.txt. Öffnet man diese Datei in einem Texteditor (z.B. Notepad++ oder dem Windows Editor – auf keinen Fall MS Word), sieht man verschiedene Optionen, den Import einzustellen.
Verpflichtend sind dabei die Angabe einer Mailadresse, an die Nachrichten über den Fortschritt des Imports gesendet werden sollen (Achtung: Die Mailadresse muss einem Benutzerkonto in musdb, das mindestens die Benutzerrolle „Museumsdirektor“ hat, zugeordnet sein), und die Angabe des „Parsers“, kurz gesagt, des nötigen Import-Formats.
Eine Liste der Import-Formate mit ihren Benennungen findet sich am Ende der Datei. So möglich, stehen hier auch die möglichen parser-spezifischen Einstellungen aufgelistet. So lässt sich etwa für den Parser „ImagesByInvno", also dem Importieren von Bildern nach einer im Dateinamen angegebenen Inventarnummer, einstellen, wie lang die Inventarnummer sein soll, oder ob die Inventarnummer über die ersten 10 (11, 12, 13, …) Buchstaben ermittelt werden soll, oder über ein Trennzeichen (überblicherweise ein Unterstrich) ermittelt werden soll.
Weitere allgemeine Einstellungen sind optional. So kann eingestellt werden, ob die Objekte gleich nach dem Import veröffentlicht werden sollen, oder ob sie alle in eine spezifische Sammlung importiert werden sollen. In der Datei finden sich zu jedem dieser Punkte relativ ausführliche Erläuterungen.
Ist die Import-Konfiguration soweit abgeschlossen, kann die Datei in import_config.txt umbennant werden. Das vorhandensein einer Datei mit diesem Namen auf der obersten Ebene des WebDAV-Laufwerks ist das Zeichen an den Server, dass importiert werden soll.
Der Import findet statt
Für das automatische Importieren prüft der Server alle vier Stunden, ob sich passende Importdateien in den WebDAV-Verzeichnissen befinden (also, Daten hochgeladen wurden, und eine Datei import_config.txt vorhanden ist). Ist das der Fall, läuft der Import ab.
Sobald es einen Fehler gibt wird der Import abgebrochen und eine Fehlermail an die in der Konfigurationsdatei angegebene Mailadresse und das Entwicklerteam gesendet. Fehler können z.B. bei einer bisher unbekannte Lizenzangabe vorliegen, aber auch schlicht unlogisch formulierte Daten betreffen. Bei Parsern mit Vollständigkeitsprüfung kann der Fehler auftreten, dass ein bestimmtes Datum bisher nicht vom Parser abgedeckt wird.
Im Fehlerfall werden die Importdaten dann in einem Ordner IMPORTS_FAILED verschoben. Sobald der Parser oder die Daten angepasst wurden, damit der Fehler nicht mehr auftritt, können sie von dort wieder an die richtige Stelle für ausstehende Importe (also die Ordner IMPORT_XML und IMPORT_IMG) verschoben werden.
Läuft der Import andererseits fehlerfrei durch, wird eine Benachrichtigungsmail an die oben angegebene Adresse gesendet.
Nötige Anpassungen für die Ermöglichung von benutzergesteuerten Importen
Damit all das möglich wurde, mussten wir den Importer großflächig anpassen. Gerade für die Konfigurierbarkeit von parserspezifischen Werten brauchte es auf Seiten der Parser eine grundlegend andere Architektur.
Der Importer besteht grundlegend aus vier Arten von Scripten:
- Eine Repräsentation der grundlegenden importierbaren Datentypen (Objekte, Ereignisse, Bilder, Sammlungen) in Code
- Scripte, die das Schreiben von Daten in die Datenbank übernehmen
- Parsern, die den Ablauf eines Imports für die verschiedenen Arten von Importdaten und die Zuordnungen von Werten aus den Importdateien zu den bei museum-digital bestehenden Datentypen herstellen
- Frontend-Scripten, die z.B. das Kommandozeilen-Interface bereitstellen
Von diesen waren bisher nur die Datentypen und Schreib-Scripte mit einem objektorientierten Ansatz geschrieben. Für die neue Möglichkeit selbst zu importieren, wurden auch die Parser und die Frontend-Scripte angepasst, sodass das ganze Importtool jetzt mithilfe eines objektorientierten Ansatzes geschrieben ist. Das hat u.a. auch den Vorteil, dass für alle vorhandenen Parser automatische Tests eingerichtet werden konnten, sodass z.B. Fehler, die durch Updates der Programmiersprache oder Änderungen an anderen Stellen entstehen, frühzeitig auffallen und gelöst werden können.
Der Anspruch automatisierte Tests für alle Aspekte des Importers zu haben führt allerdings auch dazu, dass nicht mehr alle bisher vorhandenen Parser verfügbar sind. Beim Überführen der Parser in die neue Architektur wurden solche Parser übergangen, die mit größerer Wahrscheinlichkeit nicht wieder gebraucht werden (z.B. der Parser für Museo, das alte Inventarisierungssystem der Museen der Lausitz, das seit längerem nicht mehr gepflegt wird und nicht mehr im Einsatz ist).
Und für wen ist das sinnvoll?
Wer kann also von der Möglichkeit, Daten selbst zu importieren, profitieren? Einerseits sind das Museen, die mit einem anderen Programm inventarisieren, aber ihre Daten mit museum-digital veröffentlichen und deren Daten schon einmal erfolgreich importiert wurden. In diesen Fällen ist davon auszugehen, dass das bestehende Importformat sich nicht weiter geändert hat und ein passender Parser bereitsteht.
Andererseits können Museen profitieren, die sehr viele Abbildungen für ihre Objekte haben, und bei denen der Upload mit dem regulären Bild-Uploadtool zuviel Zeit kosten würde. Im Freien Deutschen Hochstift / Frankfurter Goethe-Museum wird die Funktion etwa schon fleißig genutzt, um gescannte Handschriften zu den Metadaten-Datensätzen in musdb hochzuladen.
Für Museen, die das erste Mal importieren wollen, oder für solche, die Daten importieren möchten, für die es bisher noch keinen Parser gibt, macht der eigenständige Import andererseits keinen Sinn. In diesen Fällen weiterhin heißt es wie so oft: Einfach eine Mail schreiben, eine Lösung wird sich finden.
P.S.: Auch im Handbuch findet sich eine jeweils aktuelle Beschreibung des Import-Prozesses.